Cerebrium
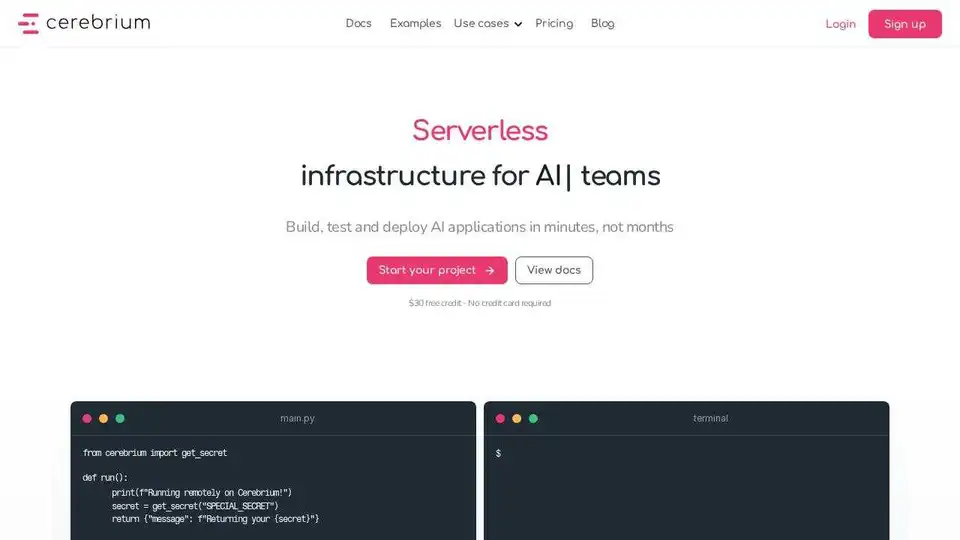
Overview of Cerebrium
Cerebrium: Serverless AI Infrastructure for Real-Time Applications
What is Cerebrium? Cerebrium is a serverless cloud infrastructure platform designed to simplify the building and deployment of AI applications. It offers scalable and performant solutions for running serverless GPUs with low cold starts, supports a wide range of GPU types, and enables large-scale batch jobs and real-time applications.
How Does Cerebrium Work?
Cerebrium simplifies the AI development workflow by addressing key challenges in configuration, development, deployment, and observability:
- Configuration: It provides easy configuration options, allowing users to set up new applications within seconds. The platform avoids complex syntax, enabling quick project initialization, hardware selection, and deployment.
- Development: Cerebrium helps streamline the development process, providing tools and features that reduce complexity.
- Deployment: The platform ensures fast cold starts (averaging 2 seconds or less) and seamless scalability, allowing applications to scale from zero to thousands of containers automatically.
- Observability: Cerebrium supports comprehensive tracking of application performance with unified metrics, traces, and logs via OpenTelemetry.
Key Features and Benefits
- Fast Cold Starts: Applications start in an average of 2 seconds or less.
- Multi-Region Deployments: Deploy applications globally for better compliance and improved performance.
- Seamless Scaling: Automatically scale applications from zero to thousands of containers.
- Batching: Combine requests into batches to minimize GPU idle time and improve throughput.
- Concurrency: Dynamically scale applications to handle thousands of simultaneous requests.
- Asynchronous Jobs: Enqueue workloads and run them in the background for training tasks.
- Distributed Storage: Persist model weights, logs, and artifacts across deployments without external setup.
- Wide Range of GPU Types: Choose from T4, A10, A100, H100, Trainium, Inferentia, and other GPUs.
- WebSocket Endpoints: Enable real-time interactions and low-latency responses.
- Streaming Endpoints: Push tokens or chunks to clients as they are generated.
- REST API Endpoints: Expose code as REST API endpoints with automatic scaling and built-in reliability.
- Bring Your Own Runtime: Use custom Dockerfiles or runtimes for complete control over application environments.
- CI/CD & Gradual Rollouts: Support CI/CD pipelines and safe, gradual rollouts for zero-downtime updates.
- Secrets Management: Securely store and manage secrets via the dashboard.
Trusted Software Layer
Cerebrium provides a trusted software layer with features like:
- Batching: Combine requests into batches, minimizing GPU idle time and improving throughput.
- Concurrency: Dynamically scale apps to handle thousands of simultaneous requests.
- Asynchronous jobs: Enqueue workloads and run them in the background - perfect for any training task
- Distributed storage: Persist model weights, logs, and artifacts across your deployment with no external setup.
- Multi-region deployments: Deploy globally by in multiple regions and give users fast, local access, wherever they are.
- OpenTelemetry: Track app performance end-to-end with unified metrics, traces, and log observability.
- 12+ GPU types: Select from T4, A10, A100, H100, Trainium, Inferentia, and other GPUs for specific use cases
- WebSocket endpoints: Real-time interactions and low-latency responses make for for better user experiences
- Streaming endpoints: Native streaming endpoints push tokens or chunks to clients as they’re generated.
- REST API endpoints: Expose code as REST API endpoints - automatic scaling and improved reliability built-in.
Use Cases
Cerebrium is suitable for:
- LLMs: Deploy and scale large language models.
- Agents: Build and deploy AI agents.
- Vision Models: Deploy vision models for various applications.
- Video Processing: Scaled human-like AI experiences.
- Generative AI: Breaking language barriers with Lelapa AI.
- Digital avatars: Scaling digital humans for Virtual assistants with bitHuman
Who is Cerebrium For?
Cerebrium is designed for startups and enterprises looking to scale their AI applications without the complexities of DevOps. It is particularly useful for those working with LLMs, AI agents, and vision models.
Pricing
Cerebrium offers a pay-only-for-what-you-use pricing model. Users can estimate their monthly costs based on compute requirements, hardware selection (CPU only, L4, L40s, A10, T4, A100 (80GB), A100 (40GB), H100, H200 GPUs, etc.), and memory requirements.
Why is Cerebrium Important?
Cerebrium simplifies the deployment and scaling of AI applications, enabling developers to focus on building innovative solutions. Its serverless infrastructure, wide range of GPU options, and comprehensive features make it a valuable tool for anyone working with AI.
In conclusion, Cerebrium is a serverless AI infrastructure platform that offers a comprehensive set of features for deploying and scaling real-time AI applications. With its easy configuration, seamless scaling, and trusted software layer, Cerebrium simplifies the AI development workflow and enables businesses to focus on innovation. The platform supports various GPU types, asynchronous jobs, distributed storage, and multi-region deployments, making it suitable for a wide range of AI applications and use cases.
Best Alternative Tools to "Cerebrium"

Baseten is a platform for deploying and scaling AI models in production. It offers performant model runtimes, cross-cloud high availability, and seamless developer workflows, powered by the Baseten Inference Stack.

Float16.cloud offers serverless GPUs for AI development. Deploy models instantly on H100 GPUs with pay-per-use pricing. Ideal for LLMs, fine-tuning, and training.

Friendli Inference is the fastest LLM inference engine, optimized for speed and cost-effectiveness, slashing GPU costs by 50-90% while delivering high throughput and low latency.

Explore NVIDIA NIM APIs for optimized inference and deployment of leading AI models. Build enterprise generative AI applications with serverless APIs or self-host on your GPU infrastructure.

Runpod is an AI cloud platform simplifying AI model building and deployment. Offering on-demand GPU resources, serverless scaling, and enterprise-grade uptime for AI developers.

GPUX is a serverless GPU inference platform that enables 1-second cold starts for AI models like StableDiffusionXL, ESRGAN, and AlpacaLLM with optimized performance and P2P capabilities.
Scade.pro is a comprehensive no-code AI platform that enables users to build AI features, automate workflows, and integrate 1500+ AI models without technical skills.

Inferless offers blazing fast serverless GPU inference for deploying ML models. It provides scalable, effortless custom machine learning model deployment with features like automatic scaling, dynamic batching, and enterprise security.

Runpod is an all-in-one AI cloud platform that simplifies building and deploying AI models. Train, fine-tune, and deploy AI effortlessly with powerful compute and autoscaling.
Deployo simplifies AI model deployment, turning models into production-ready applications in minutes. Cloud-agnostic, secure, and scalable AI infrastructure for effortless machine learning workflow.

Simplify AI deployment with Synexa. Run powerful AI models instantly with just one line of code. Fast, stable, and developer-friendly serverless AI API platform.
Modal: Serverless platform for AI and data teams. Run CPU, GPU, and data-intensive compute at scale with your own code.
ZETIC.ai enables building zero-cost on-device AI apps by deploying models directly on devices. Reduce AI service costs and secure data with serverless AI using ZETIC.MLange.
Novita AI provides 200+ Model APIs, custom deployment, GPU Instances, and Serverless GPUs. Scale AI, optimize performance, and innovate with ease and efficiency.