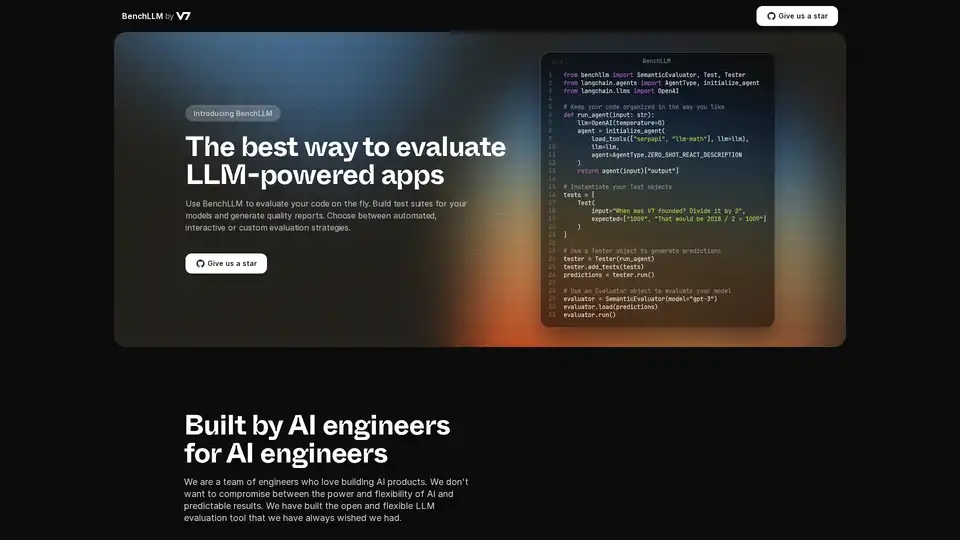
BenchLLM 概述
什么是 BenchLLM?
BenchLLM 是一个旨在评估大型语言模型 (LLM) 驱动的应用程序的性能和质量的工具。它提供了一个灵活而全面的框架,用于构建测试套件、生成质量报告和监控模型性能。无论您需要自动化、交互式还是自定义评估策略,BenchLLM 都提供所需的功能和能力,以确保您的 AI 模型满足要求的标准。
BenchLLM 如何工作?
BenchLLM 的工作方式是允许用户定义测试,针对这些测试运行模型,然后评估结果。以下是详细的分解:
- 直观地定义测试: 测试可以在 JSON 或 YAML 格式中定义,从而可以轻松设置和管理测试用例。
- 将测试组织到套件中: 将测试组织到套件中,以便于版本控制和管理。这有助于在模型演变时维护不同的测试版本。
- 运行测试: 使用强大的 CLI 或灵活的 API 针对您的模型运行测试。BenchLLM 开箱即用地支持 OpenAI、Langchain 和任何其他 API。
- 评估结果: BenchLLM 提供了多种评估策略来评估您的模型的性能。它有助于识别生产中的回归,并随着时间的推移监控模型性能。
- 生成报告: 生成评估报告并与您的团队分享。这些报告提供了对您的模型的优势和劣势的见解。
示例代码片段:
以下是如何将 BenchLLM 与 Langchain 一起使用的示例:
from benchllm import SemanticEvaluator, Test, Tester
from langchain.agents import AgentType, initialize_agent
from langchain.llms import OpenAI
## Keep your code organized in the way you like
def run_agent(input: str):
llm=OpenAI(temperature=0)
agent = initialize_agent(
load_tools(["serpapi", "llm-math"], llm=llm),
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
return agent(input)["output"]
## Instantiate your Test objects
tests = [
Test(
input="When was V7 founded? Divide it by 2",
expected=["1009", "That would be 2018 / 2 = 1009"]
)
]
## Use a Tester object to generate predictions
tester = Tester(run_agent)
tester.add_tests(tests)
predictions = tester.run()
## Use an Evaluator object to evaluate your model
evaluator = SemanticEvaluator(model="gpt-3")
evaluator.load(predictions)
evaluator.run()
以下是如何将 BenchLLM 与 OpenAI 的 ChatCompletion API 一起使用的示例:
import benchllm
from benchllm.input_types import ChatInput
import openai
def chat(messages: ChatInput):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.content.strip()
@benchllm.test(suite=".")
def run(input: ChatInput):
return chat(input)
主要特性和优势
- 灵活的 API: 通过支持 OpenAI、Langchain 和其他 API,随时随地测试代码。
- 强大的 CLI: 使用简单的 CLI 命令运行和评估模型,非常适合 CI/CD 管道。
- 轻松评估: 以 JSON 或 YAML 格式直观地定义测试。
- 自动化: 在 CI/CD 管道中自动化评估,以确保持续的质量。
- 富有洞察力的报告: 生成和共享评估报告,以监控模型性能。
- 性能监控: 通过监控模型性能来检测生产中的回归。
如何使用 BenchLLM?
- 安装: 下载并安装 BenchLLM。
- 定义测试: 在 JSON 或 YAML 中创建测试套件。
- 运行评估: 使用 CLI 或 API 针对您的 LLM 应用程序运行测试。
- 分析报告: 查看生成的报告以识别需要改进的领域。
BenchLLM 适用于谁?
BenchLLM 专为希望确保其 LLM 驱动的应用程序的质量和可靠性的 AI 工程师和开发人员而设计。它特别适用于:
- AI 工程师: 那些构建和维护 AI 产品的人员。
- 开发人员: 将 LLM 集成到他们的应用程序中。
- 团队: 寻求监控和提高其 AI 模型的性能。
为什么选择 BenchLLM?
BenchLLM 提供了一个全面的解决方案来评估 LLM 应用程序,提供灵活性、自动化和富有洞察力的报告。它由 AI 工程师构建,他们了解对强大而灵活的工具的需求,这些工具可以提供可预测的结果。通过使用 BenchLLM,您可以:
- 确保您的 LLM 应用程序的质量。
- 自动化评估过程。
- 监控模型性能并检测回归。
- 通过富有洞察力的报告改进协作。
通过选择 BenchLLM,您选择了一个强大而可靠的解决方案来评估您的 AI 模型,并确保它们满足最高的性能和质量标准。
"BenchLLM"的最佳替代工具

Confident AI 是一个基于 DeepEval 构建的 LLM 评估平台,帮助工程团队测试、基准测试、保障和提升 LLM 应用性能。它提供一流的指标、防护措施和可观测性,用于优化 AI 系统并捕获回归问题。

Openlayer是一个企业级AI平台,为从ML到LLM的AI系统提供统一的AI评估、可观测性和治理。在整个AI生命周期中测试、监控和管理AI系统。
UpTrain 是一个全栈 LLMOps 平台,提供企业级工具,用于评估、实验、监控和测试 LLM 应用程序。在您自己的安全云环境中托管,并自信地扩展 AI。
PromptLayer 是一个 AI 工程平台,用于提示管理、评估和 LLM 可观察性。与专家协作,监控 AI 代理,并使用强大的工具提高提示质量。
Gentrace 帮助追踪、评估和分析 AI 代理的错误。与 AI 聊天以调试追踪,自动化评估,并微调 LLM 产品以实现可靠的性能。今天免费开始!
Athina是一个协作AI平台,帮助团队更快10倍构建、测试和监控基于LLM的功能。提供提示管理、评估和可观察性工具,确保数据隐私并支持自定义模型。
Query Vary 是一个无需代码的平台,允许团队协作训练 AI 并构建 AI 驱动的自动化。 它集成了生成式 AI,无需编程即可优化工作流程并提高生产力。
FinetuneDB 是一个 AI 微调平台,让您快速创建和管理数据集,以低成本训练自定义 LLM,通过生产数据和协作工具提升模型性能。