Groq
Übersicht von Groq
Groq: Die Infrastruktur für Inferenz
Was ist Groq?
Groq ist ein Unternehmen, das sich auf die Bereitstellung schneller Inferenzlösungen für KI-Entwickler konzentriert. Ihr Hauptangebot ist die LPU™ Inference Engine, eine Hardware- und Softwareplattform, die für außergewöhnliche Rechengeschwindigkeit, Qualität und Energieeffizienz entwickelt wurde. Groq bietet sowohl Cloud-basierte (GroqCloud™) als auch On-Premise-Lösungen (GroqRack™) an, um verschiedenen Bereitstellungsanforderungen gerecht zu werden.
Wie funktioniert Groq?
Groqs LPU™ (Language Processing Unit) wurde speziell für Inferenz entwickelt, d. h. sie wurde speziell für die Phase entwickelt, in der trainierte KI-Modelle eingesetzt und zur Vorhersage oder Generierung von Ausgaben verwendet werden. Dies steht im Gegensatz zur Anpassung von Allzweck-Hardware für Inferenz. Die LPU™ wird in den USA mit einer widerstandsfähigen Lieferkette entwickelt, um eine konsistente Leistung in großem Maßstab zu gewährleisten. Dieser Fokus auf Inferenz ermöglicht es Groq, Geschwindigkeit, Kosten und Qualität kompromisslos zu optimieren.
Wesentliche Merkmale und Vorteile von Groq:
- Unübertroffenes Preis-Leistungs-Verhältnis: Groq bietet die niedrigsten Kosten pro Token, selbst wenn die Nutzung steigt, ohne Abstriche bei Geschwindigkeit, Qualität oder Kontrolle. Dies macht es zu einer kosteneffizienten Lösung für umfangreiche KI-Bereitstellungen.
- Geschwindigkeit in jeder Größenordnung: Groq bietet eine Latenz von weniger als einer Millisekunde, selbst bei starkem Datenverkehr, in verschiedenen Regionen und für unterschiedliche Arbeitslasten. Diese konstante Leistung ist entscheidend für KI-Anwendungen in Echtzeit.
- Modellqualität, der Sie vertrauen können: Die Architektur von Groq bewahrt die Modellqualität in jeder Größenordnung, von kompakten Modellen bis hin zu umfangreichen Mixture of Experts (MoE)-Modellen. Dies gewährleistet genaue und zuverlässige KI-Vorhersagen.
GroqCloud™ Plattform
GroqCloud™ ist eine Full-Stack-Plattform, die schnelle, erschwingliche und produktionsreife Inferenz bietet. Sie ermöglicht es Entwicklern, die Technologie von Groq nahtlos mit nur wenigen Codezeilen zu integrieren.
GroqRack™ Cluster
GroqRack™ bietet On-Premise-Zugriff auf die Technologie von Groq. Es wurde für Unternehmenskunden entwickelt und bietet ein unübertroffenes Preis-Leistungs-Verhältnis.
Warum ist Groq wichtig?
Inferenz ist eine kritische Phase im KI-Lebenszyklus, in der trainierte Modelle zum Einsatz kommen. Der Fokus von Groq auf eine optimierte Inferenzinfrastruktur begegnet den Herausforderungen der Bereitstellung von KI-Modellen in großem Maßstab und gewährleistet sowohl Geschwindigkeit als auch Kosteneffizienz.
Wo kann ich Groq einsetzen?
Die Lösungen von Groq können in einer Vielzahl von KI-Anwendungen eingesetzt werden, darunter:
- Large Language Models (LLMs)
- Voice Models
- Verschiedene KI-Anwendungen, die schnelle Inferenz erfordern
Wie man mit Groq zu entwickeln beginnt:
Groq bietet einen kostenlosen API-Schlüssel, damit Entwickler die Technologie von Groq schnell evaluieren und integrieren können. Die Plattform bietet außerdem Groq-Bibliotheken und -Demos, um Entwicklern den Einstieg zu erleichtern. Sie können Groq kostenlos ausprobieren, indem Sie die Website besuchen und sich für ein Konto anmelden.
Groq begrüßt den KI-Aktionsplan der Trump-Administration, beschleunigt die globale Bereitstellung des amerikanischen AI Stack und Groq startet europäischen Datenzentrums-Footprint in Helsinki, Finnland.
Zusammenfassend lässt sich sagen, dass Groq eine leistungsstarke Inferenz-Engine für KI ist. Groq bietet Cloud- und On-Prem-Lösungen in großem Maßstab für KI-Anwendungen. Mit seinem Fokus auf Geschwindigkeit, Kosteneffizienz und Modellqualität ist Groq gut positioniert, um eine Schlüsselrolle in der Zukunft von KI-Bereitstellungen zu spielen. Wenn Sie auf der Suche nach schneller und zuverlässiger KI-Inferenz sind, ist Groq eine Plattform, die Sie in Betracht ziehen sollten.
Beste Alternativwerkzeuge zu "Groq"
Spice.ai ist eine Open-Source-Daten- und KI-Inferenz-Engine zum Erstellen von KI-Apps mit SQL-Query-Federation, Beschleunigung, Suche und Abruf auf der Grundlage von Unternehmensdaten.
Local AI ist eine kostenlose Open-Source-Native-Anwendung, die das Experimentieren mit KI-Modellen lokal vereinfacht. Es bietet CPU-Inferenz, Modellverwaltung und Digest-Verifizierung und benötigt keine GPU.
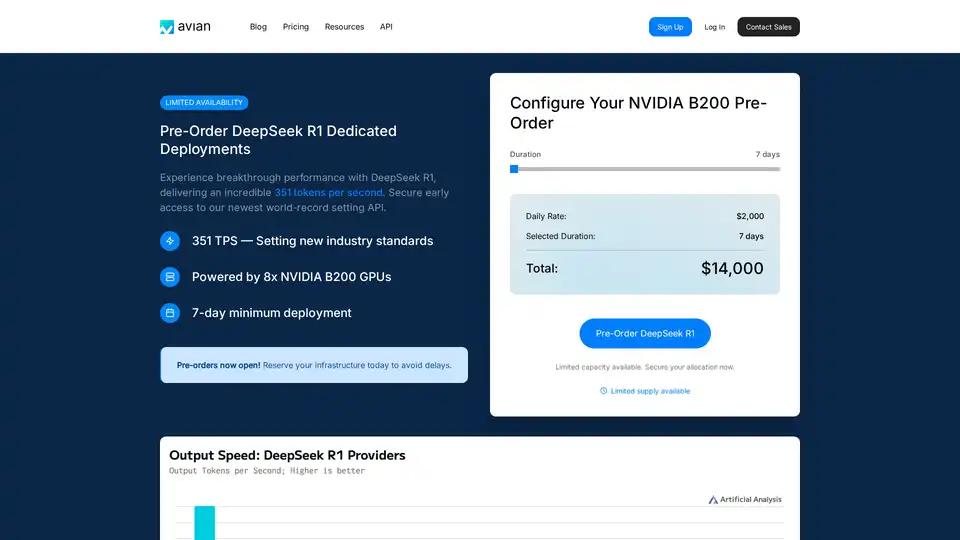
Avian API bietet die schnellste KI-Inferenz für Open-Source-LLMs und erreicht 351 TPS auf DeepSeek R1. Stellen Sie jeden HuggingFace LLM mit einer 3-10-fachen Geschwindigkeit mit einer OpenAI-kompatiblen API bereit. Enterprise-Grade-Performance und Datenschutz.
Nexa SDK ermöglicht schnelle und private KI-Inferenz auf dem Gerät für LLMs, multimodale, ASR- und TTS-Modelle. Stellen Sie auf Mobilgeräten, PCs, in der Automobilindustrie und auf IoT-Geräten mit produktionsbereiter Leistung auf NPU, GPU und CPU bereit.
PremAI ist ein angewandtes KI-Forschungslabor, das sichere, personalisierte KI-Modelle, verschlüsselte Inferenz mit TrustML™ und Open-Source-Tools wie LocalAI zur lokalen Ausführung von LLMs bereitstellt.
AI Runner ist eine Offline-KI-Inferenz-Engine für Kunst, Echtzeit-Sprachkonversationen, LLM-gestützte Chatbots und automatisierte Arbeitsabläufe. Führen Sie Bilderzeugung, Voice-Chat und mehr lokal aus!
Experimentieren Sie lokal mit KI-Modellen ohne technische Einrichtung mit local.ai, einer kostenlosen Open-Source-Native-App, die für Offline-KI-Inferenz entwickelt wurde. Keine GPU erforderlich!
PremAI ist ein KI-Forschungslabor, das sichere, personalisierte KI-Modelle für Unternehmen und Entwickler bereitstellt. Zu den Funktionen gehören TrustML-verschlüsselte Inferenz und Open-Source-Modelle.
Awan LLM bietet eine uneingeschränkte und kostengünstige LLM-Inferenz-API-Plattform mit unbegrenzten Token, ideal für Entwickler und Power-User. Verarbeiten Sie Daten, vervollständigen Sie Code und erstellen Sie KI-Agenten ohne Token-Limits.
Nebius ist eine KI-Cloud-Plattform, die entwickelt wurde, um die KI-Infrastruktur zu demokratisieren und eine flexible Architektur, getestete Leistung und langfristigen Wert mit NVIDIA-GPUs und optimierten Clustern für Training und Inferenz bietet.
SaladCloud bietet eine erschwingliche, sichere und Community-gesteuerte verteilte GPU-Cloud für KI/ML-Inferenz. Sparen Sie bis zu 90 % der Rechenkosten. Ideal für KI-Inferenz, Stapelverarbeitung und mehr.
BrainHost VPS bietet Hochleistungs-KVM-Virtueller-Server mit NVMe-Speicher, ideal für KI-Inferenz, Websites und E-Commerce. Schnelle 30-Sekunden-Bereitstellung in Hongkong und US-West für zuverlässigen globalen Zugriff.
Denvr Dataworks bietet hochleistungsfähige KI-Rechenservices, darunter On-Demand-GPU-Cloud, KI-Inferenz und eine private KI-Plattform. Beschleunigen Sie Ihre KI-Entwicklung mit NVIDIA H100, A100 und Intel Gaudi HPUs.

GPUX ist eine serverlose GPU-Inferenzplattform, die 1-Sekunden-Kaltstarts für KI-Modelle wie StableDiffusionXL, ESRGAN und AlpacaLLM mit optimierter Leistung und P2P-Fähigkeiten ermöglicht.