BenchLLM
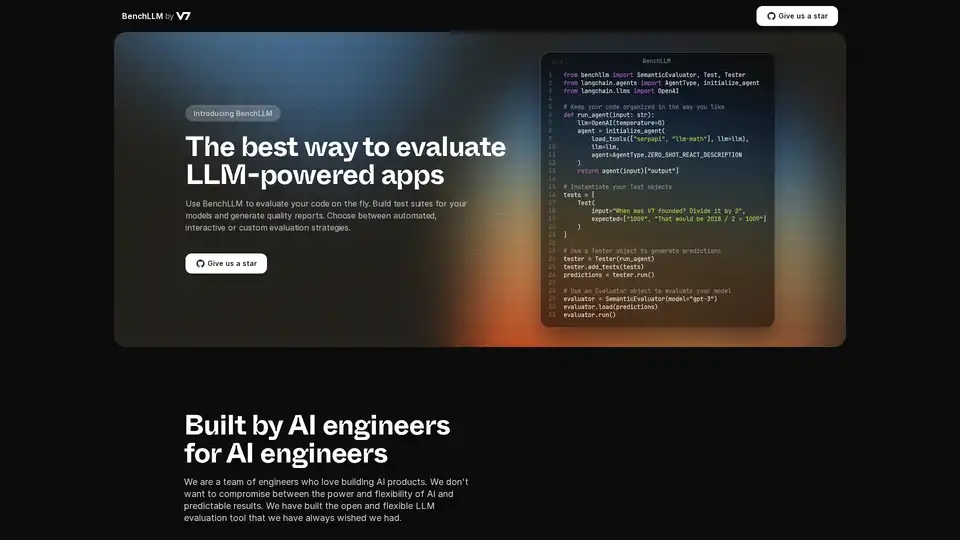
Übersicht von BenchLLM
Was ist BenchLLM?
BenchLLM ist ein Tool, das entwickelt wurde, um die Leistung und Qualität von Anwendungen zu bewerten, die auf Large Language Models (LLMs) basieren. Es bietet ein flexibles und umfassendes Framework zum Erstellen von Testsuiten, zum Generieren von Qualitätsberichten und zur Überwachung der Modellleistung. Egal, ob Sie automatisierte, interaktive oder benutzerdefinierte Evaluierungsstrategien benötigen, BenchLLM bietet die Funktionen und Möglichkeiten, um sicherzustellen, dass Ihre AI-Modelle die erforderlichen Standards erfüllen.
Wie funktioniert BenchLLM?
BenchLLM funktioniert, indem es Benutzern ermöglicht, Tests zu definieren, Modelle anhand dieser Tests auszuführen und dann die Ergebnisse zu bewerten. Hier ist eine detaillierte Aufschlüsselung:
- Tests intuitiv definieren: Tests können im JSON- oder YAML-Format definiert werden, wodurch das Einrichten und Verwalten von Testfällen vereinfacht wird.
- Tests in Suiten organisieren: Organisieren Sie Tests in Suiten, um eine einfache Versionierung und Verwaltung zu ermöglichen. Dies hilft bei der Pflege verschiedener Testversionen, während sich die Modelle weiterentwickeln.
- Tests ausführen: Verwenden Sie die leistungsstarke CLI oder die flexible API, um Tests für Ihre Modelle auszuführen. BenchLLM unterstützt OpenAI, Langchain und jede andere API standardmäßig.
- Ergebnisse bewerten: BenchLLM bietet mehrere Evaluierungsstrategien zur Bewertung der Leistung Ihrer Modelle. Es hilft, Regressionen in der Produktion zu identifizieren und die Modellleistung im Laufe der Zeit zu überwachen.
- Berichte generieren: Generieren Sie Evaluierungsberichte und teilen Sie sie mit Ihrem Team. Diese Berichte geben Einblicke in die Stärken und Schwächen Ihrer Modelle.
Beispielcode-Schnipsel:
Hier ist ein Beispiel für die Verwendung von BenchLLM mit Langchain:
from benchllm import SemanticEvaluator, Test, Tester
from langchain.agents import AgentType, initialize_agent
from langchain.llms import OpenAI
## Keep your code organized in the way you like
def run_agent(input: str):
llm=OpenAI(temperature=0)
agent = initialize_agent(
load_tools(["serpapi", "llm-math"], llm=llm),
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
return agent(input)["output"]
## Instantiate your Test objects
tests = [
Test(
input="When was V7 founded? Divide it by 2",
expected=["1009", "That would be 2018 / 2 = 1009"]
)
]
## Use a Tester object to generate predictions
tester = Tester(run_agent)
tester.add_tests(tests)
predictions = tester.run()
## Use an Evaluator object to evaluate your model
evaluator = SemanticEvaluator(model="gpt-3")
evaluator.load(predictions)
evaluator.run()
Hier ist ein Beispiel für die Verwendung von BenchLLM mit der ChatCompletion API von OpenAI:
import benchllm
from benchllm.input_types import ChatInput
import openai
def chat(messages: ChatInput):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.content.strip()
@benchllm.test(suite=".")
def run(input: ChatInput):
return chat(input)
Hauptmerkmale und Vorteile
- Flexible API: Testen Sie Code im laufenden Betrieb mit Unterstützung für OpenAI, Langchain und andere APIs.
- Leistungsstarke CLI: Führen Sie Modelle mit einfachen CLI-Befehlen aus und bewerten Sie sie. Ideal für CI/CD-Pipelines.
- Einfache Evaluierung: Definieren Sie Tests intuitiv im JSON- oder YAML-Format.
- Automatisierung: Automatisieren Sie Evaluierungen innerhalb einer CI/CD-Pipeline, um eine kontinuierliche Qualität sicherzustellen.
- Aufschlussreiche Berichte: Generieren und teilen Sie Evaluierungsberichte, um die Modellleistung zu überwachen.
- Leistungsüberwachung: Erkennen Sie Regressionen in der Produktion, indem Sie die Modellleistung überwachen.
Wie verwende ich BenchLLM?
- Installation: Laden Sie BenchLLM herunter und installieren Sie es.
- Tests definieren: Erstellen Sie Testsuiten in JSON oder YAML.
- Evaluierungen ausführen: Verwenden Sie die CLI oder API, um Tests für Ihre LLM-Anwendungen auszuführen.
- Berichte analysieren: Überprüfen Sie die generierten Berichte, um Bereiche mit Verbesserungspotenzial zu identifizieren.
Für wen ist BenchLLM geeignet?
BenchLLM wurde für AI-Ingenieure und -Entwickler entwickelt, die die Qualität und Zuverlässigkeit ihrer LLM-basierten Anwendungen sicherstellen möchten. Es ist besonders nützlich für:
- AI-Ingenieure: Diejenigen, die AI-Produkte entwickeln und warten.
- Entwickler: Die LLMs in ihre Anwendungen integrieren.
- Teams: Die die Leistung ihrer AI-Modelle überwachen und verbessern möchten.
Warum BenchLLM wählen?
BenchLLM bietet eine umfassende Lösung zur Bewertung von LLM-Anwendungen und bietet Flexibilität, Automatisierung und aufschlussreiche Berichte. Es wurde von AI-Ingenieuren entwickelt, die das Bedürfnis nach leistungsstarken und flexiblen Tools verstehen, die vorhersagbare Ergebnisse liefern. Durch die Verwendung von BenchLLM können Sie:
- Die Qualität Ihrer LLM-Anwendungen sicherstellen.
- Den Evaluierungsprozess automatisieren.
- Die Modellleistung überwachen und Regressionen erkennen.
- Die Zusammenarbeit mit aufschlussreichen Berichten verbessern.
Mit der Wahl von BenchLLM entscheiden Sie sich für eine robuste und zuverlässige Lösung zur Bewertung Ihrer AI-Modelle und stellen sicher, dass diese die höchsten Leistungs- und Qualitätsstandards erfüllen.
Beste Alternativwerkzeuge zu "BenchLLM"
LangWatch ist eine Plattform für KI-Agenten-Tests, LLM-Evaluierung und LLM-Observability. Testen Sie Agenten, verhindern Sie Regressionen und beheben Sie Probleme.

Bolt Foundry bietet Context-Engineering-Tools, um KI-Verhalten vorhersagbar und testbar zu machen, und hilft Ihnen so, vertrauenswürdige LLM-Produkte zu entwickeln. Testen Sie LLMs wie Sie Code testen.

Confident AI ist eine auf DeepEval basierende LLM-Evaluierungsplattform, die Ingenieurteams befähigt, die Leistung von LLM-Anwendungen zu testen, zu bewerten, zu sichern und zu verbessern. Sie bietet erstklassige Metriken, Schutzmaßnahmen und Beobachtbarkeit zur Optimierung von KI-Systemen und zum Aufdecken von Regressionen.
Future AGI bietet eine einheitliche LLM Observability- und KI-Agenten-Evaluierungsplattform für KI-Anwendungen, die Genauigkeit und verantwortungsvolle KI von der Entwicklung bis zur Produktion gewährleistet.
PromptLayer ist eine KI-Engineering-Plattform für Prompt-Management, -Bewertung und LLM-Observability. Arbeiten Sie mit Experten zusammen, überwachen Sie KI-Agenten und verbessern Sie die Prompt-Qualität mit leistungsstarken Tools.

Openlayer ist eine KI-Unternehmensplattform, die eine einheitliche KI-Bewertung, Observability und Governance für KI-Systeme von ML bis LLMs bietet. Testen, überwachen und verwalten Sie KI-Systeme während des gesamten KI-Lebenszyklus.
Freeplay ist eine KI-Plattform, die Teams bei der Entwicklung, dem Testen und der Verbesserung von KI-Produkten durch Prompt-Management, Evaluierungen, Observability und Datenprüfungsworkflows unterstützt. Sie optimiert die KI-Entwicklung und gewährleistet eine hohe Produktqualität.
Vivgrid ist eine KI-Agenten-Infrastrukturplattform, die Entwicklern hilft, KI-Agenten mit Sicherheitsvorkehrungen und Inferenz mit niedriger Latenz zu erstellen, zu beobachten, zu bewerten und bereitzustellen. Es unterstützt GPT-5, Gemini 2.5 Pro und DeepSeek-V3.
Future AGI ist eine einheitliche LLM-Observability- und KI-Agenten-Evaluierungsplattform, die Unternehmen dabei hilft, durch umfassende Test-, Evaluierungs- und Optimierungswerkzeuge 99% Genauigkeit in KI-Anwendungen zu erreichen.
Maxim AI ist eine End-to-End-Bewertungs- und Observability-Plattform, die Teams dabei unterstützt, KI-Agenten zuverlässig und 5-mal schneller bereitzustellen, mit umfassenden Test-, Überwachungs- und Qualitätssicherungswerkzeugen.
UpTrain ist eine Full-Stack-LLMOps-Plattform, die Tools der Enterprise-Klasse zur Bewertung, zum Experimentieren, Überwachen und Testen von LLM-Anwendungen bereitstellt. Hosten Sie in Ihrer eigenen sicheren Cloud-Umgebung und skalieren Sie KI zuverlässig.
Promptfoo ist ein Open-Source-LLM-Sicherheitstool, das von über 200.000 Entwicklern für AI Red-Teaming und Bewertungen verwendet wird. Es hilft, Schwachstellen zu finden, die Ausgabequalität zu maximieren und Regressionen in KI-Anwendungen abzufangen.
Athina ist eine kollaborative AI-Plattform, die Teams dabei hilft, LLM-basierte Funktionen 10-mal schneller zu entwickeln, zu testen und zu überwachen. Mit Tools für Prompt-Management, Evaluierungen und Observability gewährleistet sie Datenschutz und unterstützt benutzerdefinierte Modelle.
Trainieren, verwalten und evaluieren Sie benutzerdefinierte große Sprachmodelle (LLMs) schnell und effizient auf Entry Point AI, ohne dass Code erforderlich ist.