Thunder Compute
Übersicht von Thunder Compute
Thunder Compute: Erschwingliche und zugängliche GPU-Cloud-Plattform
Was ist Thunder Compute?
Thunder Compute ist eine GPU-Cloud-Plattform, die für Forscher, Startups und Data Scientists entwickelt wurde, die an KI- und Machine-Learning-Projekten arbeiten. Sie bietet One-Click-GPU-Instanzen, die deutlich günstiger sind und behauptet, 80 % billiger zu sein als Wettbewerber wie AWS. Dies erleichtert und verbilligt den Zugriff auf die erforderliche Rechenleistung für anspruchsvolle AI/ML-Aufgaben.
Wie funktioniert Thunder Compute?
Thunder Compute vereinfacht die Einrichtung und Verwaltung von GPU-Instanzen. Benutzer können in Sekundenschnelle dedizierte GPUs hochfahren und direkt in VS Code, einem beliebten Code-Editor, entwickeln. Zu den Hauptmerkmalen gehören:
- One-Click-Setup: Schnelles Starten einer GPU-Instanz ohne komplexe Konfigurationen.
- VS Code-Integration: Entwickeln und deployen Sie direkt aus Ihrer vertrauten VS Code-Umgebung.
- Hardware-Flexibilität: Einfaches Austauschen von Hardware-Konfigurationen, um sie an die Anforderungen Ihres Projekts anzupassen.
- Persistent Environment: Beibehalten einer konsistenten Entwicklungsumgebung.
Hauptmerkmale und Vorteile
- Kosteneinsparungen: Die Plattform bietet eine On-Demand-Preisgestaltung, die deutlich niedriger ist als bei AWS, sodass Entwickler auf leistungsstarken GPUs wie A100 entwickeln können, ohne das Budget zu sprengen.
- Vereinfachtes Setup: Thunder Compute beseitigt die Komplexität herkömmlicher GPU-Setups, wodurch SSH-Schlüssel, CUDA-Installationen und manuelle Abhängigkeitsverwaltung überflüssig werden.
- Schnelle Entwicklung: Die VS Code-Erweiterung und die Instanzvorlagen rationalisieren den Entwicklungsprozess, sodass Benutzer ihre Projekte in Sekundenschnelle statt in Tagen zum Laufen bringen können.
- Skalierbarkeit: Ändern Sie die Instanzspezifikationen (vCPUs, RAM, Speicher) einfach mit wenigen Klicks, um sie an sich ändernde Projektanforderungen anzupassen.
- Instanzvorlagen: Vorkonfigurierte Vorlagen sind für beliebte Tools wie Ollama und Comfy-ui verfügbar, sodass Benutzer schnell mit ihren bevorzugten Frameworks beginnen können.
Für wen ist Thunder Compute geeignet?
Thunder Compute ist ideal für:
- Forscher: Zugriff auf erschwingliche GPU-Ressourcen für AI/ML-Forschungsprojekte.
- Startups: Reduzieren Sie die Infrastrukturkosten und beschleunigen Sie die Entwicklung für AI-gesteuerte Anwendungen.
- Data Scientists: Schnelles Prototyping und Skalieren von Machine-Learning-Modellen.
- Machine Learning Engineers: Optimieren Sie den Entwicklungs- und Bereitstellungsprozess.
Warum ist Thunder Compute wichtig?
Thunder Compute demokratisiert den Zugang zu GPU-Computing und macht es für eine breitere Palette von Benutzern erschwinglicher und zugänglicher. Durch die Vereinfachung der Einrichtung und Verwaltung von GPU-Instanzen ermöglicht Thunder Compute es Entwicklern, sich auf die Entwicklung innovativer AI/ML-Anwendungen zu konzentrieren, ohne durch Kosten oder Komplexität eingeschränkt zu werden.
Testimonials
- "Die VS Code-Erweiterung hilft mir, schneller zu iterieren. Alles, was Papier-Deadlines weniger stressig macht, ist ein Gewinn." - PhD in Machine Learning, U.C. Berkeley
- "Ich liefere schneller und unser CEO liebt die Einsparungen. Bisher habe ich neun unserer MLEs zum Wechseln überzeugt." - ML Engineer, Series B startup
- "Der Mehrwert ist Wahnsinn. Wir sind bootstrapped und führen rund um die Uhr 2-3 Fine-Tuning-Jobs aus." - Co-founder, Data Science Consultancy
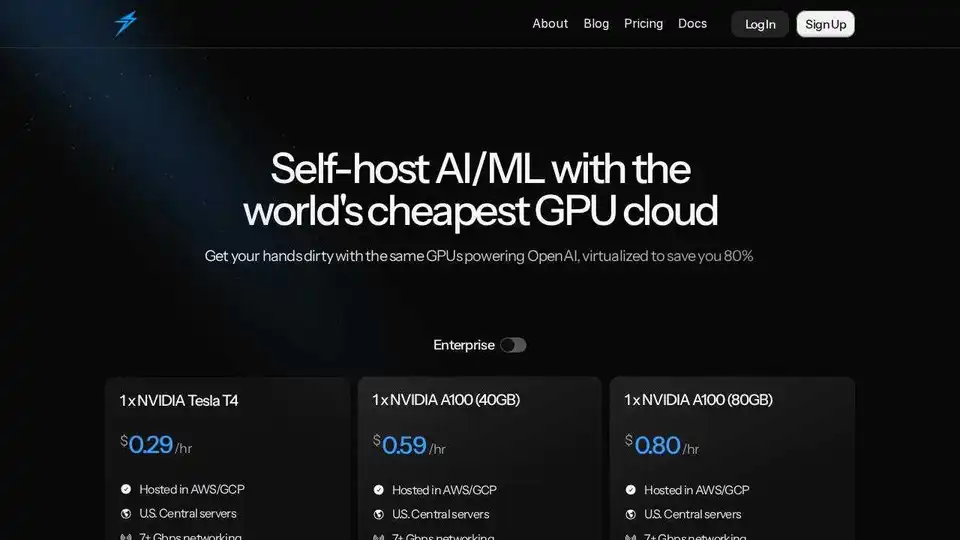
Preise
Thunder Compute bietet wettbewerbsfähige On-Demand-Preise für verschiedene GPU-Konfigurationen, darunter:
- Tesla T4
- A100 40GB
- A100 80GB
Benutzer können vCPUs, RAM und Speicher an ihre spezifischen Bedürfnisse anpassen. Während der Beta-Phase gleicht Thunder Compute 100 % des ersten Guthabenkaufs bis zu 50 $ aus.
Zusammenfassend bietet Thunder Compute eine überzeugende Lösung für alle, die eine erschwingliche und zugängliche GPU-Computing-Lösung für die AI/ML-Entwicklung suchen. Das One-Click-Setup, die VS Code-Integration und die wettbewerbsfähigen Preise machen es zu einem wertvollen Werkzeug für Forscher, Startups und Data Scientists.
Beste Alternativwerkzeuge zu "Thunder Compute"
Anyscale, powered by Ray, ist eine Plattform zum Ausführen und Skalieren aller ML- und KI-Workloads in jeder Cloud oder On-Premises-Umgebung. Erstellen, debuggen und implementieren Sie KI-Anwendungen einfach und effizient.
SaladCloud bietet eine erschwingliche, sichere und Community-gesteuerte verteilte GPU-Cloud für KI/ML-Inferenz. Sparen Sie bis zu 90 % der Rechenkosten. Ideal für KI-Inferenz, Stapelverarbeitung und mehr.
Novita AI bietet mehr als 200 Model-APIs, benutzerdefinierte Bereitstellung, GPU-Instanzen und serverlose GPUs. Skalieren Sie die KI, optimieren Sie die Leistung und innovieren Sie mühelos und effizient.
GreenNode bietet umfassende KI-fähige Infrastruktur und Cloud-Lösungen mit H100-GPUs ab 2,34 $/Stunde. Greifen Sie auf vorkonfigurierte Instanzen und eine Full-Stack-KI-Plattform für Ihre KI-Reise zu.
Mieten Sie mit Vast.ai kostengünstig Hochleistungs-GPUs. Stellen Sie sofort GPU-Mieten für KI, maschinelles Lernen, Deep Learning und Rendering bereit. Flexible Preise und schnelle Einrichtung.

Float16.Cloud bietet serverlose GPUs für eine schnelle KI-Entwicklung. Führen Sie KI-Modelle ohne Einrichtung sofort aus, trainieren und skalieren Sie sie. Mit H100-GPUs, sekundengenauer Abrechnung und Python-Ausführung.
ChatLLaMA ist ein LoRA-trainierter KI-Assistent basierend auf LLaMA-Modellen, der benutzerdefinierte persönliche Gespräche auf Ihrem lokalen GPU ermöglicht. Mit Desktop-GUI, trainiert auf Anthropics HH-Datensatz, verfügbar für 7B-, 13B- und 30B-Modelle.
Massed Compute bietet On-Demand-GPU- und CPU-Cloud-Computing-Infrastruktur für KI, maschinelles Lernen und Datenanalyse. Greifen Sie mit flexiblen und erschwinglichen Plänen auf hochleistungsfähige NVIDIA-GPUs zu.
Lightning AI ist ein All-in-One-Cloud-Arbeitsbereich, der zum Erstellen, Bereitstellen und Trainieren von KI-Agenten, Daten und KI-Apps entwickelt wurde. Erhalten Sie Modell-APIs, GPU-Training und Multi-Cloud-Bereitstellung in einem Abonnement.

Online-KI-Manga-Übersetzer mit OCR für vertikalen/horizontalen Text. Stapelverarbeitung und layouterhaltende Typografie für Manga und Doujin.
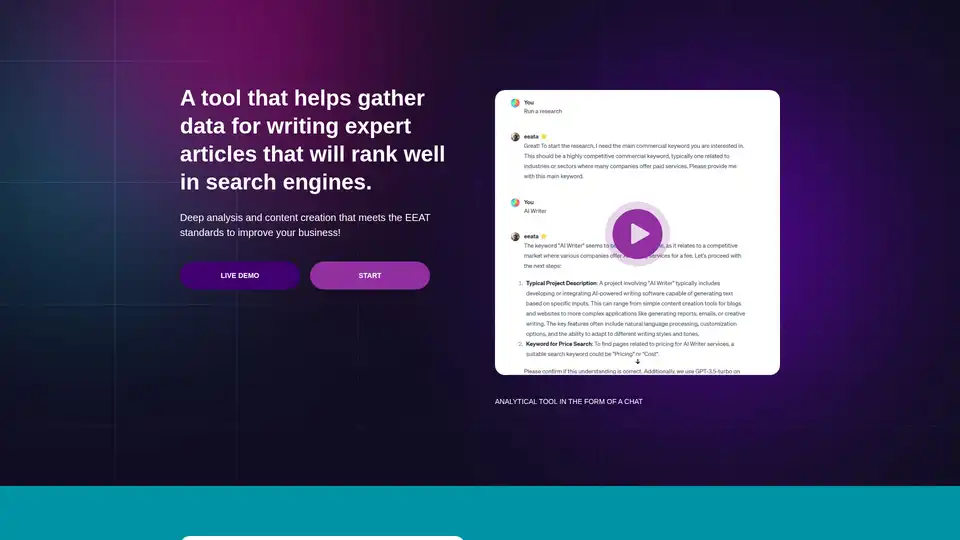
eeat ist ein KI-gestütztes Analysetool mit GPT-3.5 und GPT-4, das detaillierte Daten zu kommerziellen Keywords und Wettbewerbern sammelt, um EEAT-konformes Experten-Content zu erstellen und Suchmaschinen-Rankings sowie die Geschäftskonkurrenzfähigkeit zu steigern.
Deep Infra ist eine kostengünstige, skalierbare AI-Inferenz-Plattform mit +100 ML-Modellen wie DeepSeek-V3.2, Qwen und OCR-Tools. Entwicklerfreundliche APIs, GPU-Vermietung und Null-Datenretention.
dreamlook.ai bietet blitzschnelles Stable Diffusion Finetuning, das es Benutzern ermöglicht, Modelle 2,5x schneller zu trainieren und schnell hochwertige Bilder zu generieren. Extrahieren Sie LoRA-Dateien, um die Downloadgröße zu reduzieren.
Kostenloser AI-Flaschenhals-Rechner: Überprüfen Sie CPU/GPU-Kompatibilität in 30 Sek. Optimieren Sie Ihr System für Gaming- und Streaming-Effizienz