Avian API
Overview of Avian API
Avian API: The Fastest AI Inference for Open Source LLMs
Avian API is a platform that provides the fastest AI inference for open-source Large Language Models (LLMs) like Llama. It allows users to deploy and run LLMs from Hugging Face at speeds 3-10x faster than industry averages. With Avian, users can experience production-grade AI inference without rate limits, leveraging serverless architecture or deploying any LLM from Hugging Face.
What is Avian API?
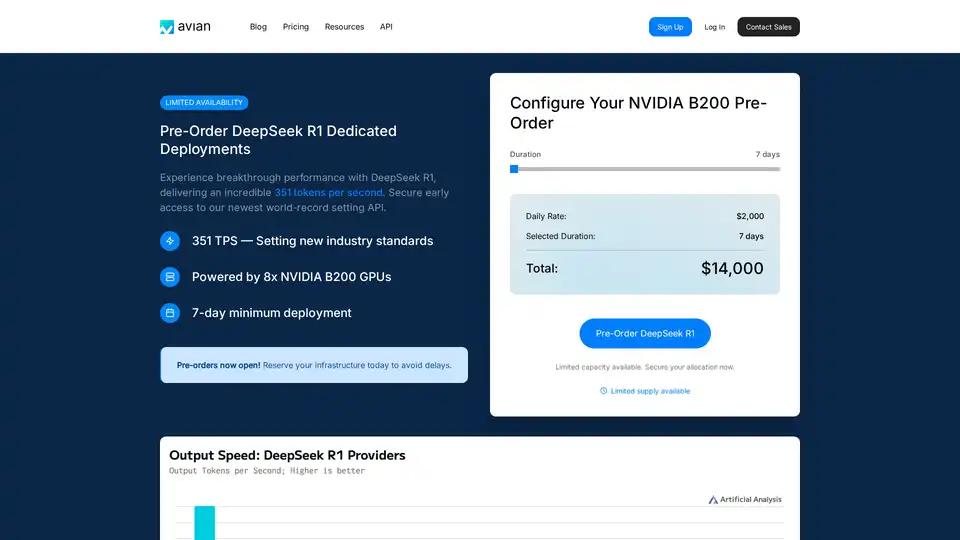
Avian API is designed to provide high-performance AI inference, focusing on speed, privacy, and ease of use. It stands out by offering industry-leading inference speeds, particularly on models like DeepSeek R1, where it achieves 351 tokens per second (TPS). This performance is powered by optimized NVIDIA B200 architecture, setting new standards in the AI inference landscape.
How does Avian API work?
Avian API works by leveraging optimized infrastructure and proprietary techniques to accelerate the inference process. Key features include:
- High-Speed Inference: Achieves up to 351 TPS on models like DeepSeek R1.
- Hugging Face Integration: Allows deployment of any Hugging Face model with minimal configuration.
- Automatic Optimization & Scaling: Automatically optimizes and scales models to ensure consistent performance.
- OpenAI-Compatible API Endpoint: Provides an easy-to-use API endpoint compatible with OpenAI, simplifying integration into existing workflows.
- Enterprise-Grade Performance & Privacy: Built on secure, SOC/2 approved Microsoft Azure infrastructure with no data storage.
Key Features and Benefits
- Fastest Inference Speeds: Avian API offers unmatched inference speed, making it ideal for applications requiring real-time responses.
- Easy Integration: With its OpenAI-compatible API, Avian can be easily integrated into existing projects with minimal code changes.
- Cost-Effective: By optimizing resource utilization, Avian helps reduce the costs associated with AI inference.
- Privacy and Security: Avian ensures data privacy and security with its SOC/2 compliance and private hosting options.
How to Use Avian API
Using Avian API involves a few simple steps:
- Sign Up: Create an account on the Avian.io platform.
- Get Your API Key: Obtain your unique API key from the dashboard.
- Select Model: Choose your preferred open-source model from Hugging Face or use DeepSeek R1 for optimal performance.
- Integrate API: Use the provided code snippet to integrate the Avian API into your application.
Here's an example code snippet for using the Avian API:
from openai import OpenAI
import os
client = OpenAI(
base_url="https://api.avian.io/v1",
api_key=os.environ.get("AVIAN_API_KEY")
)
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[
{
"role": "user",
"content": "What is machine learning?"
}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="")
This code snippet demonstrates how to use the Avian API to generate a response from the DeepSeek-R1 model. Simply change the base_url and use your API key to get started.
Why Choose Avian API?
Avian API stands out due to its focus on speed, security, and ease of use. Compared to other inference solutions, Avian offers:
- Superior Performance: Achieving 351 TPS on DeepSeek R1, significantly faster than competitors like Together, Fireworks, and Amazon.
- Simplified Deployment: One-line code integration for any Hugging Face model.
- Enterprise-Grade Security: SOC/2 compliance and privacy mode for chats.
Who is Avian API for?
Avian API is ideal for:
- Enterprises: Businesses requiring high-performance, secure, and scalable AI inference.
- Developers: Developers looking for an easy-to-use API to integrate AI into their applications.
- Researchers: Researchers needing fast and reliable inference for their AI models.
Conclusion
Avian API provides the fastest AI inference for open-source LLMs, making it an essential tool for anyone looking to leverage the power of AI in their projects. With its high-speed performance, easy integration, and enterprise-grade security, Avian API is setting new standards in the AI inference landscape. Whether you're deploying models from Hugging Face or leveraging the optimized NVIDIA B200 architecture, Avian API delivers unmatched speed and efficiency.
Best Alternative Tools to "Avian API"
CHAI AI is a leading conversational AI platform focused on research and development of generative AI models. It offers tools and infrastructure for building and deploying social AI applications, emphasizing user feedback and incentives.
Vivgrid is an AI agent infrastructure platform that helps developers build, observe, evaluate, and deploy AI agents with safety guardrails and low-latency inference. It supports GPT-5, Gemini 2.5 Pro, and DeepSeek-V3.

Unsloth AI offers open-source fine-tuning and reinforcement learning for LLMs like gpt-oss and Llama, boasting 30x faster training and reduced memory usage, making AI training accessible and efficient.
Nexa SDK enables fast and private on-device AI inference for LLMs, multimodal, ASR & TTS models. Deploy to mobile, PC, automotive & IoT devices with production-ready performance across NPU, GPU & CPU.
Nebius is an AI cloud platform designed to democratize AI infrastructure, offering flexible architecture, tested performance, and long-term value with NVIDIA GPUs and optimized clusters for training and inference.

Float16.cloud offers serverless GPUs for AI development. Deploy models instantly on H100 GPUs with pay-per-use pricing. Ideal for LLMs, fine-tuning, and training.

Friendli Inference is the fastest LLM inference engine, optimized for speed and cost-effectiveness, slashing GPU costs by 50-90% while delivering high throughput and low latency.

Enable efficient LLM inference with llama.cpp, a C/C++ library optimized for diverse hardware, supporting quantization, CUDA, and GGUF models. Ideal for local and cloud deployment.

Lightning-fast AI platform for developers. Deploy, fine-tune, and run 200+ optimized LLMs and multimodal models with simple APIs - SiliconFlow.

Try DeepSeek V3 online for free with no registration. This powerful open-source AI model features 671B parameters, supports commercial use, and offers unlimited access via browser demo or local installation on GitHub.
Spice.ai is an open source data and AI inference engine for building AI apps with SQL query federation, acceleration, search, and retrieval grounded in enterprise data.
DeepSeek-v3 is an AI model based on MoE architecture, providing stable and fast AI solutions with extensive training and multiple language support.
Fireworks AI delivers blazing-fast inference for generative AI using state-of-the-art, open-source models. Fine-tune and deploy your own models at no extra cost. Scale AI workloads globally.
DeepSeek v3 is a powerful AI-driven LLM with 671B parameters, offering API access and research paper. Try our online demo for state-of-the-art performance.