BenchLLM
Descripción general de BenchLLM
¿Qué es BenchLLM?
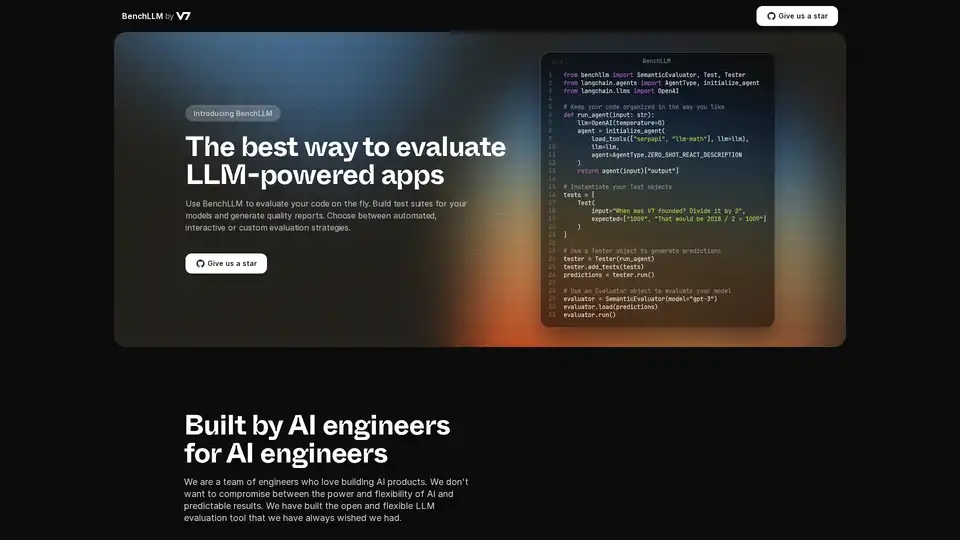
BenchLLM es una herramienta diseñada para evaluar el rendimiento y la calidad de las aplicaciones impulsadas por modelos de lenguaje grandes (LLM). Proporciona un marco de trabajo flexible y completo para construir conjuntos de pruebas, generar informes de calidad y supervisar el rendimiento del modelo. Ya sea que necesite estrategias de evaluación automatizadas, interactivas o personalizadas, BenchLLM ofrece las características y capacidades para garantizar que sus modelos de AI cumplan con los estándares requeridos.
¿Cómo funciona BenchLLM?
BenchLLM funciona permitiendo a los usuarios definir pruebas, ejecutar modelos contra esas pruebas y luego evaluar los resultados. Aquí hay un desglose detallado:
- Defina las pruebas de forma intuitiva: Las pruebas se pueden definir en formato JSON o YAML, lo que facilita la configuración y la gestión de los casos de prueba.
- Organice las pruebas en conjuntos: Organice las pruebas en conjuntos para facilitar el control de versiones y la gestión. Esto ayuda a mantener diferentes versiones de las pruebas a medida que los modelos evolucionan.
- Ejecute las pruebas: Utilice la potente CLI o la API flexible para ejecutar pruebas en sus modelos. BenchLLM admite OpenAI, Langchain y cualquier otra API de forma predeterminada.
- Evalúe los resultados: BenchLLM proporciona múltiples estrategias de evaluación para valorar el rendimiento de sus modelos. Ayuda a identificar regresiones en la producción y a supervisar el rendimiento del modelo a lo largo del tiempo.
- Genere informes: Genere informes de evaluación y compártalos con su equipo. Estos informes proporcionan información sobre las fortalezas y debilidades de sus modelos.
Fragmentos de código de ejemplo:
Aquí hay un ejemplo de cómo usar BenchLLM con Langchain:
from benchllm import SemanticEvaluator, Test, Tester
from langchain.agents import AgentType, initialize_agent
from langchain.llms import OpenAI
## Keep your code organized in the way you like
def run_agent(input: str):
llm=OpenAI(temperature=0)
agent = initialize_agent(
load_tools(["serpapi", "llm-math"], llm=llm),
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
return agent(input)["output"]
## Instantiate your Test objects
tests = [
Test(
input="When was V7 founded? Divide it by 2",
expected=["1009", "That would be 2018 / 2 = 1009"]
)
]
## Use a Tester object to generate predictions
tester = Tester(run_agent)
tester.add_tests(tests)
predictions = tester.run()
## Use an Evaluator object to evaluate your model
evaluator = SemanticEvaluator(model="gpt-3")
evaluator.load(predictions)
evaluator.run()
Aquí hay un ejemplo de cómo usar BenchLLM con la API ChatCompletion de OpenAI:
import benchllm
from benchllm.input_types import ChatInput
import openai
def chat(messages: ChatInput):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.content.strip()
@benchllm.test(suite=".")
def run(input: ChatInput):
return chat(input)
Características y ventajas principales
- API flexible: Pruebe el código sobre la marcha con soporte para OpenAI, Langchain y otras API.
- Potente CLI: Ejecute y evalúe modelos con simples comandos CLI, ideal para pipelines de CI/CD.
- Evaluación fácil: Defina pruebas de forma intuitiva en formato JSON o YAML.
- Automatización: Automatice las evaluaciones dentro de un pipeline de CI/CD para garantizar la calidad continua.
- Informes perspicaces: Genere y comparta informes de evaluación para supervisar el rendimiento del modelo.
- Supervisión del rendimiento: Detecte regresiones en la producción supervisando el rendimiento del modelo.
¿Cómo usar BenchLLM?
- Instalación: Descargue e instale BenchLLM.
- Defina las pruebas: Cree conjuntos de pruebas en JSON o YAML.
- Ejecute evaluaciones: Utilice la CLI o la API para ejecutar pruebas en sus aplicaciones LLM.
- Analice los informes: Revise los informes generados para identificar áreas de mejora.
¿Para quién es BenchLLM?
BenchLLM está diseñado para ingenieros y desarrolladores de AI que desean garantizar la calidad y la fiabilidad de sus aplicaciones impulsadas por LLM. Es particularmente útil para:
- Ingenieros de AI: Aquellos que construyen y mantienen productos de AI.
- Desarrolladores: Integración de LLM en sus aplicaciones.
- Equipos: Que buscan supervisar y mejorar el rendimiento de sus modelos de AI.
¿Por qué elegir BenchLLM?
BenchLLM proporciona una solución completa para evaluar las aplicaciones LLM, que ofrece flexibilidad, automatización e informes perspicaces. Está construido por ingenieros de AI que comprenden la necesidad de herramientas potentes y flexibles que ofrezcan resultados predecibles. Al usar BenchLLM, puede:
- Asegurar la calidad de sus aplicaciones LLM.
- Automatizar el proceso de evaluación.
- Supervisar el rendimiento del modelo y detectar regresiones.
- Mejorar la colaboración con informes perspicaces.
Al elegir BenchLLM, está optando por una solución robusta y confiable para evaluar sus modelos de AI y garantizar que cumplan con los más altos estándares de rendimiento y calidad.
Mejores herramientas alternativas a "BenchLLM"

Openlayer es una plataforma de IA empresarial que proporciona evaluación, observabilidad y gobernanza de IA unificadas para sistemas de IA, desde ML hasta LLM. Pruebe, supervise y gestione los sistemas de IA durante todo el ciclo de vida de la IA.
Athina es una plataforma colaborativa de IA que ayuda a los equipos a construir, probar y monitorear funciones basadas en LLM 10 veces más rápido. Con herramientas para gestión de prompts, evaluaciones y observabilidad, garantiza la privacidad de datos y soporta modelos personalizados.

Confident AI es una plataforma de evaluación LLM construida sobre DeepEval, que permite a los equipos de ingeniería probar, comparar, proteger y mejorar el rendimiento de las aplicaciones LLM. Ofrece métricas y salvaguardias de primer nivel, además de observabilidad para optimizar sistemas de IA y detectar regresiones.
Maxim AI es una plataforma integral de evaluación y observabilidad que ayuda a los equipos a implementar agentes de IA de manera confiable y 5 veces más rápido con herramientas completas de prueba, monitoreo y garantía de calidad.
UpTrain es una plataforma LLMOps de pila completa que proporciona herramientas de nivel empresarial para evaluar, experimentar, monitorear y probar aplicaciones LLM. Aloje en su propio entorno de nube segura y escale la IA con confianza.
PromptPoint te ayuda a diseñar, probar e implementar prompts rápidamente con pruebas automatizadas de prompts. Impulsa la ingeniería de prompts de tu equipo con salidas LLM de alta calidad.
Weco AI automatiza experimentos de aprendizaje automático usando tecnología AIDE ML, optimizando pipelines ML mediante evaluación de código impulsada por IA y experimentación sistemática para mejorar métricas de precisión y rendimiento.
Vivgrid es una plataforma de infraestructura de agentes de IA que ayuda a los desarrolladores a construir, observar, evaluar e implementar agentes de IA con protecciones de seguridad e inferencia de baja latencia. Es compatible con GPT-5, Gemini 2.5 Pro y DeepSeek-V3.
Parea AI es la plataforma definitiva de experimentación y anotación humana para equipos de IA, que permite una evaluación fluida de LLM, pruebas de prompts y despliegue en producción para construir aplicaciones de IA confiables.
EvalMy.AI automatiza la verificación de respuestas de IA y la evaluación RAG, optimizando las pruebas LLM. Garantiza precisión, configurabilidad y escalabilidad con una API fácil de usar.
RoostGPT de Roost.ai utiliza IA para automatizar la generación de casos de prueba, mejorar la precisión y cobertura de las pruebas y detectar vulnerabilidades estáticas, liberando a los desarrolladores para que se centren en la codificación y la innovación.
Teammately es el Agente de IA para Ingenieros de IA, automatizando y acelerando cada paso en la construcción de IA confiable a escala. Construye IA de grado de producción más rápido con generación de prompts, RAG y observabilidad.

Lunary es una plataforma de ingeniería LLM de código abierto que proporciona observabilidad, gestión de prompts y análisis para construir aplicaciones de IA confiables. Ofrece herramientas para la depuración, el seguimiento del rendimiento y la garantía de la seguridad de los datos.

Prueba DeepSeek V3 en línea gratis sin registro. Este potente modelo de IA de código abierto cuenta con 671B parámetros, soporta uso comercial y ofrece acceso ilimitado mediante demo en navegador o instalación local en GitHub.