Groq
Visão geral de Groq
Groq: A Infraestrutura para Inferência
O que é Groq?
Groq é uma empresa focada em fornecer soluções de inferência rápidas para construtores de AI. Sua principal oferta é o LPU™ Inference Engine, uma plataforma de hardware e software projetada para velocidade de computação, qualidade e eficiência energética excepcionais. A Groq fornece soluções baseadas em nuvem (GroqCloud™) e on-premise (GroqRack™) para atender a diversas necessidades de implantação.
Como funciona o Groq?
O LPU™ (Language Processing Unit) da Groq é construído sob medida para inferência, o que significa que ele foi projetado especificamente para o estágio em que os modelos de AI treinados são implantados e usados para fazer previsões ou gerar saídas. Isso contrasta com a adaptação de hardware de uso geral para inferência. O LPU™ é desenvolvido nos EUA com uma cadeia de suprimentos resiliente, garantindo desempenho consistente em escala. Esse foco na inferência permite que o Groq otimize a velocidade, o custo e a qualidade sem comprometer.
Principais recursos e benefícios do Groq:
- Desempenho de preço incomparável: Groq oferece o menor custo por token, mesmo com o crescimento do uso, sem sacrificar velocidade, qualidade ou controle. Isso o torna uma solução econômica para implantações de AI em grande escala.
- Velocidade em qualquer escala: Groq mantém a latência de sub-milissegundos, mesmo sob tráfego intenso, em diferentes regiões e para diferentes cargas de trabalho. Esse desempenho consistente é crucial para aplicações de AI em tempo real.
- Qualidade do modelo em que você pode confiar: A arquitetura da Groq preserva a qualidade do modelo em todas as escalas, desde modelos compactos até modelos de Mixture of Experts (MoE) em grande escala. Isso garante previsões de AI precisas e confiáveis.
Plataforma GroqCloud™
GroqCloud™ é uma plataforma full-stack que fornece inferência rápida, acessível e pronta para produção. Ele permite que os desenvolvedores integrem perfeitamente a tecnologia da Groq com apenas algumas linhas de código.
Cluster GroqRack™
GroqRack™ fornece acesso on-premise à tecnologia da Groq. Ele foi projetado para clientes empresariais e oferece desempenho de preço incomparável.
Por que o Groq é importante?
A inferência é um estágio crítico no ciclo de vida da AI, onde os modelos treinados são colocados em prática. O foco da Groq na infraestrutura de inferência otimizada aborda os desafios de implantação de modelos de AI em escala, garantindo velocidade e custo-benefício.
Onde posso usar o Groq?
As soluções da Groq podem ser usadas em uma variedade de aplicações de AI, incluindo:
- Large Language Models (LLMs)
- Voice Models
- Várias aplicações de AI que exigem inferência rápida
Como começar a construir com Groq:
A Groq fornece uma API key gratuita para permitir que os desenvolvedores avaliem e integrem rapidamente a tecnologia da Groq. A plataforma também oferece Groq Libraries e Demos para ajudar os desenvolvedores a começar. Você pode experimentar o Groq gratuitamente visitando o site e se inscrevendo para obter uma conta.
A Groq aplaude o Plano de Ação de AI da Administração Trump, acelera a implantação global do American AI Stack e Groq lança a presença do Data Center Europeu em Helsinque, Finlândia.
Em conclusão, o Groq é um mecanismo de inferência poderoso para AI. A Groq fornece soluções de nuvem e on-prem em escala para aplicações de AI. Com seu foco em velocidade, custo-benefício e qualidade do modelo, o Groq está bem posicionado para desempenhar um papel fundamental no futuro das implantações de AI. Se você está procurando inferência de AI rápida e confiável, o Groq é uma plataforma que você deve considerar.
Melhores ferramentas alternativas para "Groq"
HUMAIN fornece soluções de IA full-stack, cobrindo infraestrutura, dados, modelos e aplicações. Acelere o progresso e desbloqueie o impacto no mundo real em escala com as plataformas nativas de IA da HUMAIN.
Spice.ai é um mecanismo de inferência de dados e IA de código aberto para construir aplicativos de IA com federação de consultas SQL, aceleração, busca e recuperação baseadas em dados empresariais.
Local AI é um aplicativo nativo de código aberto e gratuito que simplifica a experimentação com modelos de IA localmente. Ele oferece inferência de CPU, gerenciamento de modelos e verificação de resumo e não requer uma GPU.
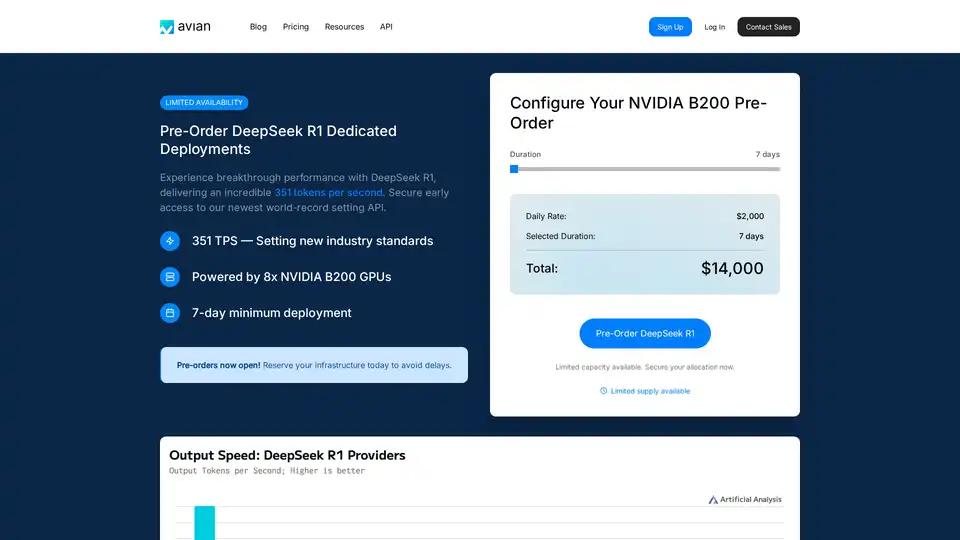
A Avian API oferece a inferência de IA mais rápida para LLMs de código aberto, atingindo 351 TPS no DeepSeek R1. Implante qualquer LLM HuggingFace com uma velocidade de 3 a 10 vezes maior com uma API compatível com OpenAI. Desempenho e privacidade de nível empresarial.
Deep Infra é uma plataforma de inferência IA escalável e de baixo custo com +100 modelos ML como DeepSeek-V3.2, Qwen e ferramentas OCR. APIs amigáveis para desenvolvedores, aluguel de GPUs e retenção zero de dados.
Nexa SDK permite inferência de IA rápida e privada no dispositivo para modelos LLM, multimodais, ASR e TTS. Implante em dispositivos móveis, PCs, automotivos e IoT com desempenho pronto para produção em NPU, GPU e CPU.
FriendliAI é uma plataforma de inferência de IA que fornece velocidade, escala e confiabilidade para a implantação de modelos de IA. Ele suporta mais de 459.400 modelos Hugging Face, oferece otimização personalizada e garante 99,99% de tempo de atividade.
Fireworks AI oferece inferência incrivelmente rápida para IA generativa usando modelos de código aberto de última geração. Ajuste e implemente seus próprios modelos sem custo extra. Escale as cargas de trabalho de IA globalmente.

GPUX é uma plataforma de inferência GPU sem servidor que permite inicializações a frio de 1 segundo para modelos de IA como StableDiffusionXL, ESRGAN e AlpacaLLM com desempenho otimizado e capacidades P2P.

Fluidstack é uma plataforma de nuvem de IA líder que oferece acesso imediato a milhares de GPUs com InfiniBand para treinamento e inferência de IA. Clusters de GPU seguros e de alto desempenho para pesquisa, empresas e iniciativas soberanas de IA.
MindSpore é um framework de IA de código aberto desenvolvido pela Huawei, suportando treinamento e inferência de aprendizado profundo em todos os cenários. Possui diferenciação automática, treinamento distribuído e implantação flexível.
AIE Labs fornece a infraestrutura para jogos e entretenimento social com IA, oferecendo criação de arte com IA, companheiros virtuais e uma rede de inferência descentralizada.
Cirrascale AI Innovation Cloud acelera o desenvolvimento de IA, o treinamento e as cargas de trabalho de inferência. Teste e implemente nos principais aceleradores de IA com alto rendimento e baixa latência.
AI Runner é um mecanismo de inferência de IA offline para arte, conversas de voz em tempo real, chatbots alimentados por LLM e fluxos de trabalho automatizados. Execute geração de imagens, chat de voz e muito mais localmente!