Avian API
Übersicht von Avian API
Avian API: Die schnellste AI-Inferenz für Open-Source-LLMs
Avian API ist eine Plattform, die die schnellste AI-Inferenz für Open-Source Large Language Models (LLMs) wie Llama bietet. Sie ermöglicht es Benutzern, LLMs von Hugging Face mit einer 3-10x höheren Geschwindigkeit als der Branchendurchschnitt bereitzustellen und auszuführen. Mit Avian können Benutzer AI-Inferenz in Produktionsqualität ohne Ratenbeschränkungen erleben, die Serverless-Architektur nutzen oder ein beliebiges LLM von Hugging Face bereitstellen.
Was ist Avian API?
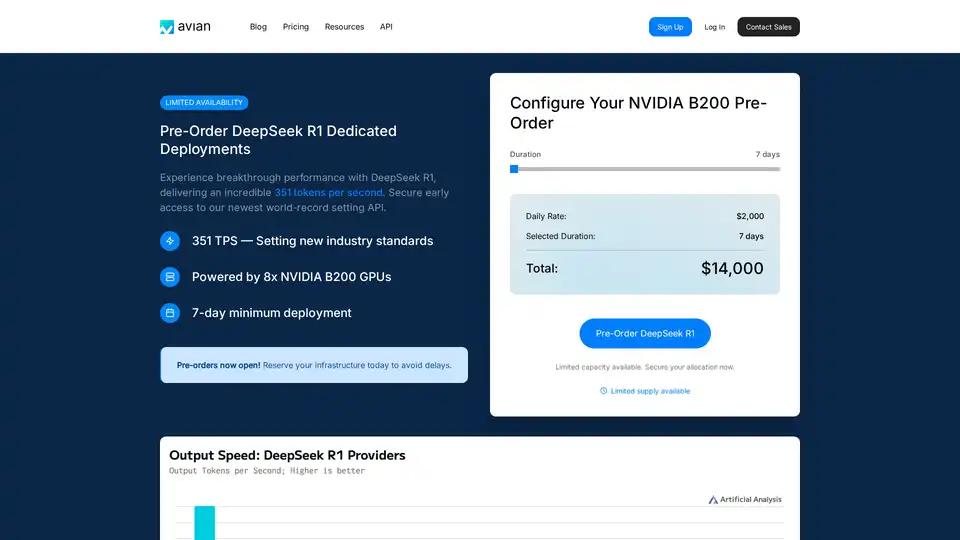
Avian API wurde entwickelt, um hochleistungsfähige AI-Inferenz bereitzustellen, wobei der Fokus auf Geschwindigkeit, Datenschutz und Benutzerfreundlichkeit liegt. Es zeichnet sich durch branchenführende Inferenzgeschwindigkeiten aus, insbesondere bei Modellen wie DeepSeek R1, wo es 351 Tokens pro Sekunde (TPS) erreicht. Diese Leistung wird durch die optimierte NVIDIA B200-Architektur ermöglicht, die neue Standards in der AI-Inferenzlandschaft setzt.
Wie funktioniert Avian API?
Avian API funktioniert durch die Nutzung optimierter Infrastruktur und proprietärer Techniken, um den Inferenzprozess zu beschleunigen. Zu den Hauptmerkmalen gehören:
- High-Speed-Inferenz: Erreicht bis zu 351 TPS bei Modellen wie DeepSeek R1.
- Hugging Face Integration: Ermöglicht die Bereitstellung jedes Hugging Face-Modells mit minimaler Konfiguration.
- Automatische Optimierung & Skalierung: Optimiert und skaliert Modelle automatisch, um eine konsistente Leistung sicherzustellen.
- OpenAI-kompatibler API-Endpunkt: Bietet einen einfach zu bedienenden API-Endpunkt, der mit OpenAI kompatibel ist und die Integration in bestehende Workflows vereinfacht.
- Enterprise-Grade Leistung & Datenschutz: Basiert auf einer sicheren, SOC/2-zertifizierten Microsoft Azure-Infrastruktur ohne Datenspeicherung.
Hauptmerkmale und Vorteile
- Schnellste Inferenzgeschwindigkeiten: Avian API bietet unübertroffene Inferenzgeschwindigkeit und ist somit ideal für Anwendungen, die Echtzeit-Antworten erfordern.
- Einfache Integration: Mit seiner OpenAI-kompatiblen API kann Avian einfach mit minimalen Codeänderungen in bestehende Projekte integriert werden.
- Kosteneffektiv: Durch die Optimierung der Ressourcenauslastung hilft Avian, die mit AI-Inferenz verbundenen Kosten zu senken.
- Datenschutz und Sicherheit: Avian gewährleistet Datenschutz und Sicherheit mit seiner SOC/2-Konformität und privaten Hosting-Optionen.
Wie man Avian API benutzt
Die Verwendung von Avian API umfasst ein paar einfache Schritte:
- Anmelden: Erstellen Sie ein Konto auf der Avian.io-Plattform.
- API-Schlüssel erhalten: Holen Sie sich Ihren eindeutigen API-Schlüssel vom Dashboard.
- Modell auswählen: Wählen Sie Ihr bevorzugtes Open-Source-Modell von Hugging Face oder verwenden Sie DeepSeek R1 für optimale Leistung.
- API integrieren: Verwenden Sie den bereitgestellten Code-Snippet, um die Avian API in Ihre Anwendung zu integrieren.
Hier ist ein Beispiel für einen Code-Snippet zur Verwendung der Avian API:
from openai import OpenAI
import os
client = OpenAI(
base_url="https://api.avian.io/v1",
api_key=os.environ.get("AVIAN_API_KEY")
)
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[
{
"role": "user",
"content": "What is machine learning?"
}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="")
Dieser Code-Snippet demonstriert, wie Sie die Avian API verwenden können, um eine Antwort vom DeepSeek-R1-Modell zu generieren. Ändern Sie einfach die base_url und verwenden Sie Ihren API-Schlüssel, um loszulegen.
Warum Avian API wählen?
Avian API zeichnet sich durch seinen Fokus auf Geschwindigkeit, Sicherheit und Benutzerfreundlichkeit aus. Im Vergleich zu anderen Inferenzlösungen bietet Avian:
- Überlegene Leistung: Erreicht 351 TPS auf DeepSeek R1, deutlich schneller als Wettbewerber wie Together, Fireworks und Amazon.
- Vereinfachte Bereitstellung: Einzeilige Code-Integration für jedes Hugging Face-Modell.
- Enterprise-Grade Sicherheit: SOC/2-Konformität und Datenschutzmodus für Chats.
Für wen ist Avian API geeignet?
Avian API ist ideal für:
- Unternehmen: Unternehmen, die hochleistungsfähige, sichere und skalierbare AI-Inferenz benötigen.
- Entwickler: Entwickler, die eine einfach zu bedienende API suchen, um AI in ihre Anwendungen zu integrieren.
- Forscher: Forscher, die eine schnelle und zuverlässige Inferenz für ihre AI-Modelle benötigen.
Fazit
Avian API bietet die schnellste AI-Inferenz für Open-Source-LLMs und ist somit ein unverzichtbares Werkzeug für alle, die die Leistungsfähigkeit von AI in ihren Projekten nutzen möchten. Mit seiner Hochgeschwindigkeitsleistung, einfachen Integration und Enterprise-Grade Sicherheit setzt Avian API neue Standards in der AI-Inferenzlandschaft. Egal, ob Sie Modelle von Hugging Face bereitstellen oder die optimierte NVIDIA B200-Architektur nutzen, Avian API bietet unübertroffene Geschwindigkeit und Effizienz.
Beste Alternativwerkzeuge zu "Avian API"
CHAI AI ist eine führende Plattform für konversationelle KI, die sich auf die Forschung und Entwicklung generativer KI-Modelle konzentriert. Sie bietet Tools und Infrastruktur für die Entwicklung und Bereitstellung sozialer KI-Anwendungen, wobei der Schwerpunkt auf Benutzerfeedback und Anreizen liegt.
Vivgrid ist eine KI-Agenten-Infrastrukturplattform, die Entwicklern hilft, KI-Agenten mit Sicherheitsvorkehrungen und Inferenz mit niedriger Latenz zu erstellen, zu beobachten, zu bewerten und bereitzustellen. Es unterstützt GPT-5, Gemini 2.5 Pro und DeepSeek-V3.
Nebius ist eine KI-Cloud-Plattform, die entwickelt wurde, um die KI-Infrastruktur zu demokratisieren und eine flexible Architektur, getestete Leistung und langfristigen Wert mit NVIDIA-GPUs und optimierten Clustern für Training und Inferenz bietet.

Friendli Inference ist die schnellste LLM-Inferenz-Engine, optimiert für Geschwindigkeit und Kosteneffizienz, die GPU-Kosten um 50-90 % senkt und gleichzeitig einen hohen Durchsatz und eine geringe Latenz bietet.

Ermöglichen Sie eine effiziente LLM-Inferenz mit llama.cpp, einer C/C++-Bibliothek, die für verschiedene Hardware optimiert ist und Quantisierung, CUDA und GGUF-Modelle unterstützt. Ideal für lokale und Cloud-Bereitstellung.

Blitzschnelle KI-Plattform für Entwickler. Bereitstellen, Feinabstimmen und Ausführen von über 200 optimierten LLMs und multimodalen Modellen mit einfachen APIs - SiliconFlow.
PremAI ist ein KI-Forschungslabor, das sichere, personalisierte KI-Modelle für Unternehmen und Entwickler bereitstellt. Zu den Funktionen gehören TrustML-verschlüsselte Inferenz und Open-Source-Modelle.
mistral.rs ist eine blitzschnelle LLM-Inferenz-Engine, geschrieben in Rust, die multimodale Workflows und Quantisierung unterstützt. Bietet Rust-, Python- und OpenAI-kompatible HTTP-Server-APIs.

Testen Sie DeepSeek V3 kostenlos online ohne Registrierung. Dieses leistungsstarke Open-Source-KI-Modell umfasst 671B Parameter, unterstützt kommerzielle Nutzung und bietet unbegrenzten Zugriff über Browser-Demo oder lokale Installation auf GitHub.
Spice.ai ist eine Open-Source-Daten- und KI-Inferenz-Engine zum Erstellen von KI-Apps mit SQL-Query-Federation, Beschleunigung, Suche und Abruf auf der Grundlage von Unternehmensdaten.
GPT4All ermöglicht die private, lokale Ausführung großer Sprachmodelle (LLMs) auf alltäglichen Desktops ohne API-Aufrufe oder GPUs. Zugängliche und effiziente LLM-Nutzung mit erweiterter Funktionalität.
Führen Sie sofort jedes Llama-Modell von HuggingFace aus, ohne Server einzurichten. Über 11.900 Modelle verfügbar. Ab 10 US-Dollar pro Monat für unbegrenzten Zugriff.

Meteron AI ist ein All-in-One-KI-Toolset, das LLM- und generative KI-Messung, Load-Balancing und Speicherung übernimmt, sodass sich Entwickler auf die Entwicklung von KI-gestützten Produkten konzentrieren können.
DeepSeek v3 ist ein leistungsstarkes KI-gestütztes LLM mit 671B Parametern, das API-Zugriff und ein Forschungspapier bietet. Testen Sie unsere Online-Demo für hochmoderne Leistung.