Massed Compute の概要
Massed Compute: 高性能AIインフラストラクチャへのゲートウェイ
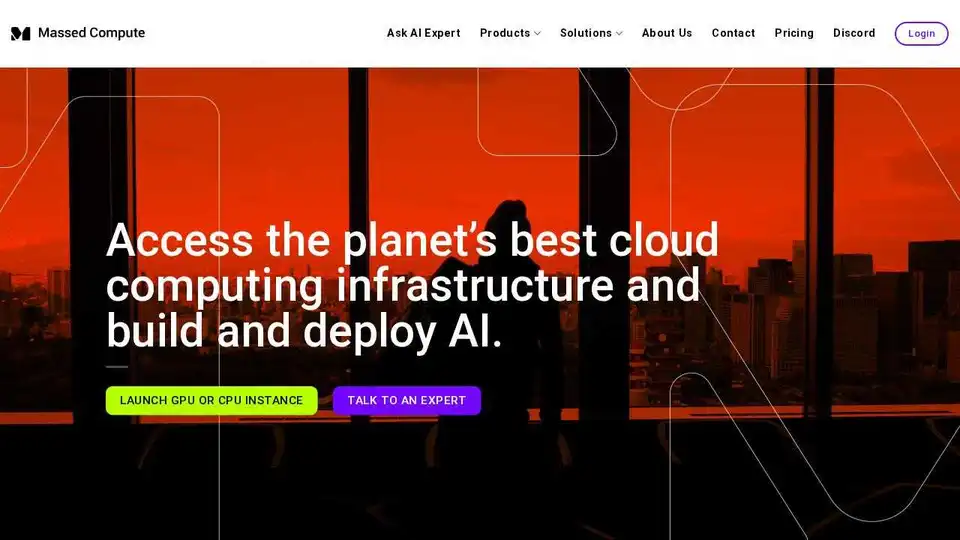
Massed Computeとは? Massed Computeは、AI、機械学習、およびデータ集約型アプリケーション向けのGPUおよびCPUソリューションに特化した、最高水準のクラウドコンピューティングインフラストラクチャへのアクセスを提供します。ベアメタルサーバー、オンデマンドコンピューティング、Inventory APIなど、スタートアップから大企業まで、多様なニーズに対応する幅広いサービスを提供しています。
Massed Computeはどのように機能しますか? Massed Computeは、自社のインフラストラクチャを所有および運営しており、仲介業者なしでコンピューティング能力に直接アクセスできます。これにより、最適化されたパフォーマンス、強化されたセキュリティ、および比類のない信頼性が保証されます。ユーザーは迅速に展開し、柔軟で手頃な価格のプランでリソースを拡張できます。
主な機能と利点:
- ベアメタルサーバー: 物理サーバーに直接アクセスして、最大のパフォーマンスと制御を実現します。データ量の多いワークロードやAIトレーニングに最適です。
- オンデマンドコンピューティング: 長期的な契約なしに、GPUとCPUのパワーを時間単位でレンタルし、比類のない稼働時間と制御を提供します。
- Inventory API: NVIDIA GPUをプラットフォームにシームレスに統合し、最高水準のGPUリソースでビジネスを強化します。
- 完全なNVIDIA GPUカタログ: エンタープライズグレードのNVIDIA GPUの全範囲にアクセスして、パフォーマンスと予算を最適化します。
- 手頃な価格設定: 必要なときに必要なものを過払いなしで入手し、時間単位のレンタルと帯域幅の超過料金なしでメリットを得られます。
- 専門家によるサポート: 推論の最適化とNVIDIAドライバーに関する深い知識を持つIT専門家と直接話すことができます。
- 仮想デスクトップインターフェイス: コマンドラインを必要とせずに、ユーザーフレンドリーなデスクトップインターフェイスを介してGPUとCPUのパワーにアクセスします。
- 信頼できるNVIDIAパートナー: 効果的な機械学習モデルのトレーニング、シミュレーション、およびデータ分析を保証する、高性能GPUテクノロジーのメリットを享受できます。
- Tier IIIデータセンターサーバー: 要求の厳しいアプリケーション向けに設計された、高度な冗長性と効率的な冷却システムにより、一貫した稼働時間を実現します。
Massed Computeの使用方法
- ソリューションを選択してください: ベアメタルサーバー、オンデマンドコンピューティングから選択するか、Inventory APIを既存のプラットフォームに統合します。
- リソースを構成します: GPUクラスターをカスタマイズするか、GPUとCPUのパワーを時間単位でレンタルします。
- 展開とスケーリング: インスタンスを迅速に起動し、必要に応じてリソースをスケーリングします。
- APIまたは仮想デスクトップを介したアクセス: シームレスな統合にはAPIを使用し、ユーザーフレンドリーなエクスペリエンスには仮想デスクトップインターフェイスを使用します。
Massed Computeが重要な理由
Massed Computeは、高性能コンピューティングへのアクセスを民主化し、スタートアップや企業にとって手頃な価格でアクセスできるようにします。自社のインフラストラクチャを所有および運営することにより、要求の厳しいAIおよびデータ集約型アプリケーションに信頼性が高く安全な環境を提供します。専門家によるサポートにより、ユーザーはリソースを最大限に活用できます。
Massed Computeの対象者
Massed Computeは、以下のような場合に最適です。
- AIおよび機械学習エンジニア
- データサイエンティスト
- AI搭載アプリケーションを構築するスタートアップ
- スケーラブルなGPUリソースを必要とする企業
- 研究者と学者
よくある質問への回答:
- AIおよびディープラーニングに最適なGPUはどれですか? Massed Computeは、A100、H100、L40、A6000など、さまざまなGPUを提供しており、それぞれ異なるワークロードに適しています。当社の専門家が、お客様のニーズに合ったGPUの選択をお手伝いします。
- GPUレンタルはスタートアップにどのように役立ちますか? GPUレンタルは、スタートアップにハードウェアを購入するための設備投資なしに、高性能コンピューティングリソースへのアクセスを提供します。これにより、開発を加速し、迅速にスケーリングできます。
結論として、Massed Computeは、オンデマンドGPUおよびCPUコンピューティング、専門家によるサポート、および手頃な価格設定を提供する、堅牢で柔軟なAIインフラストラクチャソリューションを提供します。機械学習モデルのトレーニング、シミュレーションの実行、ビッグデータの分析など、Massed Computeは目標の達成に役立ちます。
"Massed Compute" のベストな代替ツール
Vast.aiで高性能GPUを低コストでレンタル。 AI、機械学習、深層学習、レンダリング用のGPUレンタルを即座に展開。 柔軟な価格設定と迅速なセットアップ。
Buzzi.aiは、業界固有のニーズに合わせた安全で統合されたAIソリューションを通じて、業務タスクを自動化し、運用効率を向上させ、成長を促進するカスタムAIエージェントを開発します。

Runpodは、AIモデルの構築とデプロイメントを簡素化するAIクラウドプラットフォームです。 AI開発者向けに、オンデマンドGPUリソース、サーバーレススケーリング、およびエンタープライズグレードの稼働時間を提供します。
dstackは、オープンソースのAIコンテナオーケストレーションエンジンであり、MLチームにクラウド、Kubernetes、およびオンプレミス全体でのGPUプロビジョニングとオーケストレーションのための統合されたコントロールプレーンを提供します。開発、トレーニング、および推論を効率化します。
Nebius は、AI インフラストラクチャを民主化するために設計された AI クラウド プラットフォームであり、柔軟なアーキテクチャ、テスト済みのパフォーマンス、およびトレーニングと推論のために NVIDIA GPU と最適化されたクラスターによる長期的な価値を提供します。
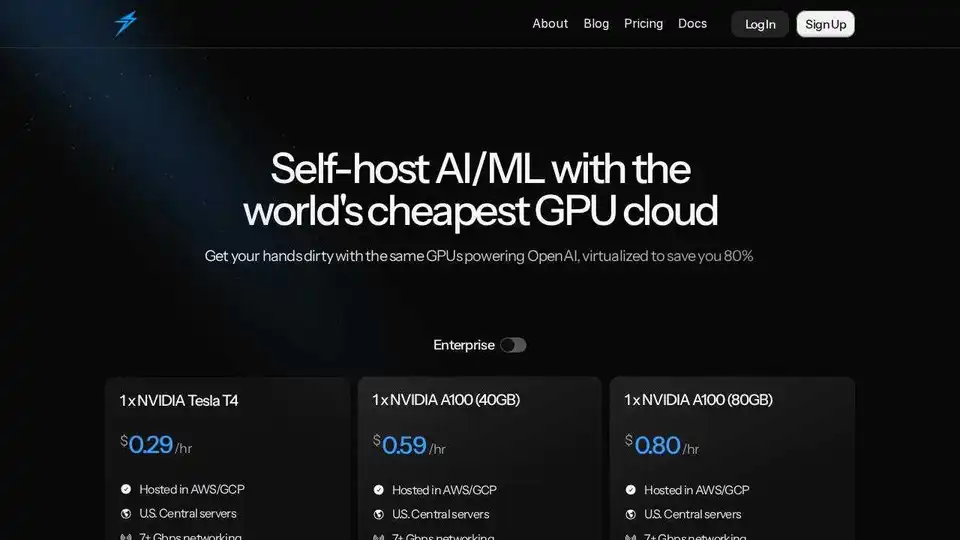
Thunder Computeは、AI/ML向けのGPUクラウドプラットフォームで、VSCodeでワンクリックGPUインスタンスを提供し、価格は競合他社より80%低くなっています。研究者、スタートアップ、データサイエンティストに最適です。
Cirrascale AI Innovation Cloudは、AI開発、トレーニング、推論のワークロードを加速します。 高スループットと低遅延で、主要なAIアクセラレータでテストおよびデプロイします。
DeployoはAIモデルのデプロイメントを簡素化し、モデルを数分で本番環境対応のアプリケーションに変換します。クラウドに依存せず、安全でスケーラブルなAIインフラストラクチャにより、簡単な機械学習ワークフローを実現します。
Luminoは、グローバルクラウドプラットフォームでのAIトレーニング用の使いやすいSDKです。 MLトレーニングコストを最大80%削減し、他では利用できないGPUにアクセスします。 今すぐAIモデルのトレーニングを開始してください!

Inferlessは、MLモデルをデプロイするための超高速なサーバーレスGPU推論を提供します。自動スケーリング、動的バッチ処理、企業セキュリティなどの機能により、スケーラブルで簡単なカスタム機械学習モデルのデプロイを実現します。
Anyscaleは、Rayを搭載し、あらゆるクラウドまたはオンプレミスですべてのMLおよびAIワークロードを実行および拡張するためのプラットフォームです。AIアプリケーションを簡単かつ効率的に構築、デバッグ、およびデプロイします。

Baseten は、本番環境で AI モデルをデプロイおよびスケーリングするためのプラットフォームです。Baseten Inference Stack を利用して、高性能なモデルランタイム、クロスクラウドの高可用性、シームレスな開発者ワークフローを提供します。

開発者向けの超高速AIプラットフォーム。シンプルなAPIで200以上の最適化されたLLMとマルチモーダルモデルをデプロイ、ファインチューニング、実行 - SiliconFlow。