Groq
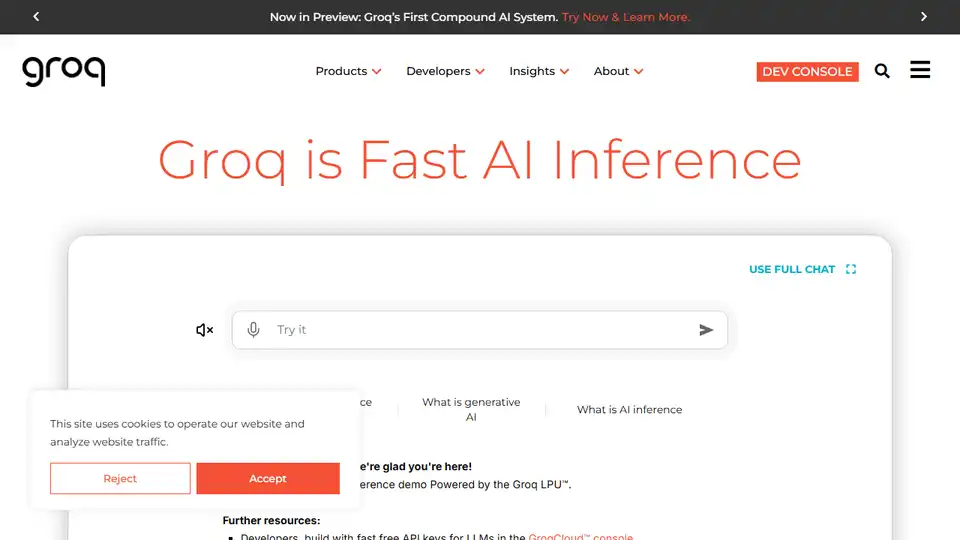
Overview of Groq
Groq: The Infrastructure for Inference
What is Groq?
Groq is a company focused on providing fast inference solutions for AI builders. Their primary offering is the LPU™ Inference Engine, a hardware and software platform designed for exceptional compute speed, quality, and energy efficiency. Groq provides both cloud-based (GroqCloud™) and on-premise (GroqRack™) solutions to cater to various deployment needs.
How does Groq work?
Groq's LPU™ (Language Processing Unit) is custom-built for inference, meaning it's designed specifically for the stage where trained AI models are deployed and used to make predictions or generate outputs. This contrasts with adapting general-purpose hardware for inference. The LPU™ is developed in the U.S. with a resilient supply chain, ensuring consistent performance at scale. This focus on inference allows Groq to optimize for speed, cost, and quality without compromise.
Key Features and Benefits of Groq:
- Unmatched Price Performance: Groq offers the lowest cost per token, even as usage grows, without sacrificing speed, quality, or control. This makes it a cost-effective solution for large-scale AI deployments.
- Speed at Any Scale: Groq maintains sub-millisecond latency even under heavy traffic, across different regions, and for varying workloads. This consistent performance is crucial for real-time AI applications.
- Model Quality You Can Trust: Groq's architecture preserves model quality at every scale, from compact models to large-scale Mixture of Experts (MoE) models. This ensures accurate and reliable AI predictions.
GroqCloud™ Platform
GroqCloud™ is a full-stack platform that provides fast, affordable, and production-ready inference. It allows developers to seamlessly integrate Groq's technology with just a few lines of code.
GroqRack™ Cluster
GroqRack™ provides on-premise access to Groq's technology. It is designed for enterprise customers and delivers unmatched price performance.
Why is Groq important?
Inference is a critical stage in the AI lifecycle where trained models are put to work. Groq's focus on optimized inference infrastructure addresses the challenges of deploying AI models at scale, ensuring both speed and cost-effectiveness.
Where can I use Groq?
Groq's solutions can be used across a variety of AI applications, including:
- Large Language Models (LLMs)
- Voice Models
- Various AI Applications Requiring Fast Inference
How to start building with Groq:
Groq provides a free API key to allow developers to quickly evaluate and integrate Groq's technology. The platform also offers Groq Libraries and Demos to help developers get started. You can try Groq for free by visiting their website and signing up for an account.
Groq Applauds Trump Administration’s AI Action Plan, Accelerates Global Deployment of the American AI Stack and Groq Launches European Data Center Footprint in Helsinki, Finland.
In conclusion, Groq is a powerful inference engine for AI. Groq provides cloud and on-prem solutions at scale for AI applications. With its focus on speed, cost-effectiveness, and model quality, Groq is well-positioned to play a key role in the future of AI deployments. If you are looking for fast and reliable AI inference, Groq is a platform that you should consider.
Best Alternative Tools to "Groq"
HUMAIN provides full-stack AI solutions, covering infrastructure, data, models, and applications. Accelerate progress and unlock real-world impact at scale with HUMAIN's AI-native platforms.
Spice.ai is an open source data and AI inference engine for building AI apps with SQL query federation, acceleration, search, and retrieval grounded in enterprise data.
Nebius AI Studio Inference Service offers hosted open-source models for faster, cheaper, and more accurate results than proprietary APIs. Scale seamlessly with no MLOps needed, ideal for RAG and production workloads.
Avian API offers the fastest AI inference for open source LLMs, achieving 351 TPS on DeepSeek R1. Deploy any HuggingFace LLM at 3-10x speed with an OpenAI-compatible API. Enterprise-grade performance and privacy.
FriendliAI is an AI inference platform that provides speed, scale, and reliability for deploying AI models. It supports 459,400+ Hugging Face models, offers custom optimization, and ensures 99.99% uptime.
Deep Infra is a platform for low-cost, scalable AI inference with 100+ ML models like DeepSeek-V3.2, Qwen, and OCR tools. Offers developer-friendly APIs, GPU rentals, zero data retention, and US-based secure infrastructure for production AI workloads.
AI Runner is an offline AI inference engine for art, real-time voice conversations, LLM-powered chatbots, and automated workflows. Run image generation, voice chat, and more locally!

GPUX is a serverless GPU inference platform that enables 1-second cold starts for AI models like StableDiffusionXL, ESRGAN, and AlpacaLLM with optimized performance and P2P capabilities.
Nexa SDK enables fast and private on-device AI inference for LLMs, multimodal, ASR & TTS models. Deploy to mobile, PC, automotive & IoT devices with production-ready performance across NPU, GPU & CPU.

Cloudflare Workers AI allows you to run serverless AI inference tasks on pre-trained machine learning models across Cloudflare's global network, offering a variety of models and seamless integration with other Cloudflare services.
Awan LLM offers an unrestricted and cost-effective LLM inference API platform with unlimited tokens, ideal for developers and power users. Process data, complete code, and build AI agents without token limits.
AIE Labs provides the infrastructure for AI social entertainment & games, offering AI art creation, virtual companions, and a decentralized inference network.
Nebius is an AI cloud platform designed to democratize AI infrastructure, offering flexible architecture, tested performance, and long-term value with NVIDIA GPUs and optimized clusters for training and inference.
SaladCloud offers affordable, secure, and community-driven distributed GPU cloud for AI/ML inference. Save up to 90% on compute costs. Ideal for AI inference, batch processing, and more.